情感分析
情感分析
1.情感分析实验总体思路是对已有的外卖评价,利用三种来源的词向量(词向量的来源有Word2vec、Glove和BERT等),将文本映射到向量空间后,利用聚类(HCM,KNN,层次聚类法)聚类,其中聚类方式中可以选择的距离公式大致分为三种:欧式距离、余弦距离和MWD距离。利用这些不同的组合得出一个表现最好的模型组合。
数据集为某外卖平台的评价信息,首先要对数据集进行预处理,为了更加客观的体现出对该商家的评价,不需要在预处理中进行平衡数据集的处理。在预处理之前,首先要了解分词的一些知识。
英文因为本身已经由空格分隔开,所以可以按照空格分词,而中文则需要分词工具去分词。中文分词是指将文本分割成多个词语,网上有人说在数据集较少时直接采用直接分字的效果可能会更好,这个有待验证。中文分词中最常用的分词工具莫过于Jieba分词(在python环境下十分常用),其框架图如下所示:
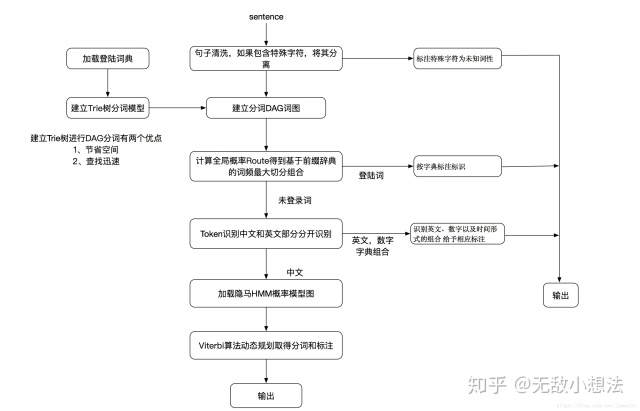
Jieba 分词支持三种分词模式,分别是精确模式、全模式和搜索引擎模式。精确模式能将句子较精确地切分成词语,适合文本分析;全模式运行速度非常快,可以扫描出所有可以生成词语的词语,但是无法解决歧义问题;而搜索引擎模式在精准模式的基础上会再一次细化地切开长词,提高了分词的召回率,适合用于搜索引擎分词。另外它还支持自定义词典(在有些专有领域内的词原词典可能并不含有,这时候可以加入额外的词典作为辅助),支持繁体分词。结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
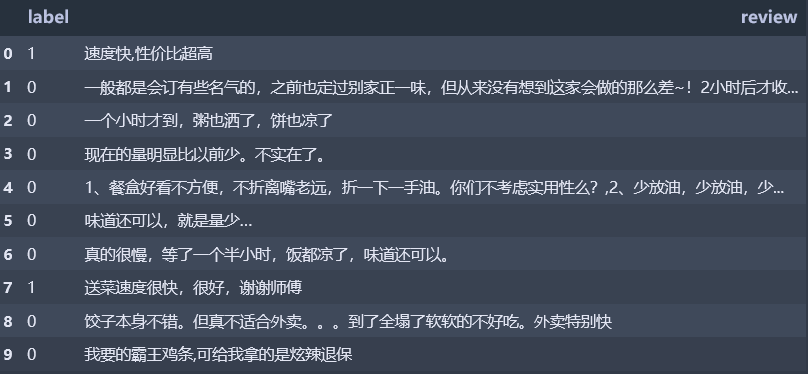
2.数据介绍:数据集采用的外卖数据集waimai_10k,原数据总共有11987条数据,其中正向数据4000条(label为1),负向数据7987条(label为0)。数据集中最长的句子为427(去掉无关符号后),最短的句子为3。最初数据是按正向然后负向类型的数据排布的,因此需要随机打乱数据集,打乱数据后,前10行数据如下所示,并将其保存为外卖原始数据集.npy,用于后续的词向量生成,并将前2400条数据作为测试集(分割比例为0.2):
2.1Bert
Bert as service服务是腾讯AI Lab 开源的一个服务,可以仅仅通过几行代码就能实现对Bert的调用,在此实践过程中,我们用此服务来生成词向量和句向量。 Bert包括两个版本,12层transfomer和24层transfomer,官网上提供了12层的中文版本的模型(哈工大也有bert的中文版本,可能效果会更好,但用bert as service时出现了错误)。每一层transformer的输出值,理论上来说都可以作为句向量,但是到底该取哪一层呢,根据hanxiao(肖涵)大神的实验数据,最佳结果是取倒数第二层,最后一层的值太接近于目标,前面几层的值可能语义还未充分的学习到。
Bert原文中的句向量采用的是句子的第一个csl对应的向量,而bert as service的句向量是怎么生成的?查阅资料可大致得,其生成过程为:
接下来是句向量生成的核心代码,这里定义了两个方法,一个mul_mask 和一个masked_reduce_mean,我们先看masked_reduce_mean(encoder_layer, input_mask)这里调用方法时传入的是encoder_layer即输出值,与input_mask即是否有有效文本,masked_reduce_mean 方法中又调用了mul_mask方法,即先把input_mask进行了一个维度扩展,然后与encoder_layer相乘,为什么要维度扩展呢,我们看下两个值的维度,我们还是假设序列的最大长度是20,那么encoder_layer的维度为[20,768],为了把无效的位置的内容置为0,input_mask的维度为[20],扩充之后变成了[20,1],两个值相乘,便把input_mask为0的位置的encoder_layer的值改为了0, 然后把相乘得到的值在axis=1的位置进行相加最后除以input_mask在axis=1的维度的和,然后把得到的结果添加一个别名final_encodes,,即为句向量的输出值。
这里有一个问题,在用bert as service处理输入句子时,句子之间是否需要按照|||的格式分割开?这里在获得句向量时,先将原始数据集中非中文符号都替换掉了,只保留了中文和数字。
|
|
在安装好bert as service的客户端和服务器端后,开始启动,在命令行输入下列代码, -model_dir之后跟的是下载的预训练的bert模型地址,这里采用的是谷歌版的中文bert,也可以在后面加上 -num_worker=2 来指定用户数量。
bert-serving-start -model_dir D:/deskbook/chinese_L-12_H-768_A-12
启动后,在客户端执行:
|
|
doc_vecs 是一个 numpy.ndarray ,它的每一行是一个固定长度的句子向量,长度由输入句子的最大长度决定。如果要指定长度,可以在启动服务使用 max_seq_len参数,过长的句子会被从右端截断。 最终可以得到维度为768的句向量。
用Bert时分成了两种情况,一种是将整个句子输入然后直接用bert as service 获得句向量,另一种情况是将jieba分词后的词语输入到bert,然后取词向量的平均值为句向量,后续会比较两种向量生成方式的好坏。要注意使用bert时,中文不需要分词。
2.2word2vec
(1)word2vec最常用的两种模型是CBOW和skip_gram。得到词向量后如何生成句向量是一个有待商榷的问题,目前一般是通过平均加权的方法,这种方法的缺点是:在平均词向量中,认为所有的词的重要程度是一样的,所以直接进行了相加平均。但是现实中,并不是每一个词对于当前文本的重要程度都相同,所以需要一种方法来细化每一个词对于当前文本的重要程度或贡献度。如果用LSTM做解码器的话应该就不需要纠结句向量的问题,在每一步的输入是每一个句子中的一个单词。
word2vec的生成:Gensim 是比较常用的一个 NLP 工具包,特别是其中的 word2vec 模块。对于句向量如何生成,查到的资料一些是由词向量加权平均得到(感觉这样会损失很多信息),另外Doc2vec和Bert(后续再讲)会生成句向量。keras中也有一个embedding层可以用来做word2vec。在本次实验中采用Gensim库来进行词向量的训练。
Gensim库中训练好的word2vec模型的保存方法,经过实际的测试,如果要用numpy保存成.npy文件时,再次加载会有输入上的问题,这里.以model.save()方法保存词向量,如下所示:
|
|
关于word2vec词向量的训练时,有几个参数在训练时要注意一下: *size一般在50-300之间; *根据语料大小选择iter,一般在10-25之间; *根据语料大小选择min_count,默认为5,语料大的大一点,语料小的小一点。
在用word2vec时,train和test要分开训练吗?目前网上的资料显示是分开训练,在本次实验中没有采用分开训练的方式,而是统一训练。word2vec也采用了多种获取句向量的方式。
(2)TFIDF加权平均词向量
TF_IDF(Term Frequency/Inverse Document Frequency)是信息检索领域非常重要的搜索词重要性度量;用以衡量一个关键词w对于查询(Query,可看作文档)所能提供的信息。词频(Term Frequency, TF)表示关键词w在文档Di中出现的频率。逆文档频率(Inverse Document Frequency, IDF)反映关键词的普遍程度——当一个词越普遍(即有大量文档包含这个词)时,其IDF值越低;反之,则IDF值越高。
在scikit-learn中,有两种方法进行TF-IDF的预处理。第一种方法是在用CountVectorizer类向量化之后再调用TfidfTransformer类进行预处理。第二种方法是直接用TfidfVectorizer完成向量化与TF-IDF预处理。
(3)SIF加权平均词向量(https://github.com/PrincetonML/SIF)
SIF加权平均词向量来自2017年的ICLR论文《A simple but tough-to-beat baseline for sentence embeddings》,
如果去除停用词的话,在停用词表中一般有“不”之类的词,去除这样的词后可能会对情感的分析产生影响。停用词:哈工大停用词表.txt。哈工大停用此表中共有990个词,其中包括了各种标点符号。
2.3glove
需要加载预训练的glove模型,目前查到glove有两种实现方式,一是standford的标准实现方式,另一种是安装glove-python库。目前satnford提供的方式支持Linux实现,glove-python在安装的过程中出现了bug。暂时先放一下。
到目前为止,我们已经获得了多种方式形成的句向量:
(1)bert加权平均句向量:先用bert获得每一个词的词向量,然后平均加权生成句向量;
(2)bert句向量:将一个句子整体输入bert,利用bert as service 服务获得句向量;
(3)tfidf加权word2vec句向量:利用word2vec的CBOW获得词向量,然后根据tfidf加权获得句向量;
(4)加权平均句向量: 利用word2vec的CBOW获得词向量,然后根平均加权获得句向量 ;
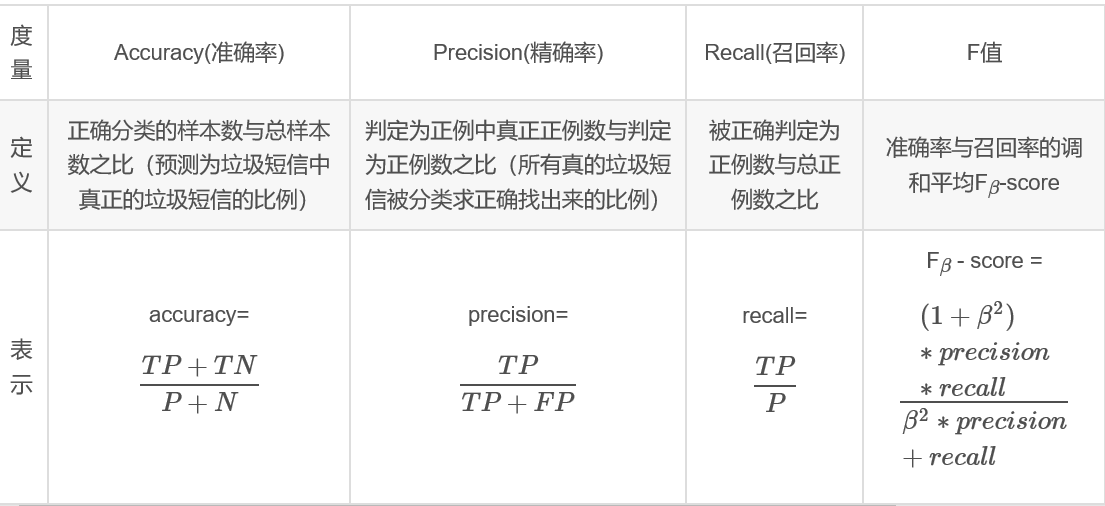
在聚类时,测试集和训练集先不划分。评价指标采用分类问题中常用的准确率、精确率、召回率、F1值:
3.实验结果
| 方法 | 数据 | 准确率 | 精确率 | 召回率 | F1 | 用时 |
|---|---|---|---|---|---|---|
| 余弦距离FCM | SIF加权句向量 | 0.548 | 0.306 | 0.280 | 0.292 | |
| KNN | SIF加权句向量 | 0.783 | 0.661 | 0.718 | 0.688 | |
| 层次聚类 | SIF加权句向量 | 0.796 | 0.702 | 0.673 | 0.687 | |
| 欧式距离FCM | bert加权平均句向量 | 0.561 | 0.101 | 0.04 | 0.057 | 1520.08(迭代42次) |
| 欧式距离FCM | 4000bert句向量(未去除符号) | 0.7095 | 0.7459 | 0.635 | 0.686 | 331.7(迭代7次) |
| 欧式距离FCM | bert句向量 | 0.578 | 0.408 | 0.590 | 0.482 | 942 |
| KNN | bert句向量 | 0.562 | 0.391 | 0.5605 | 0.4601 | 很快 |
| 层次聚类 | bert句向量 | 0.713 | 0.564 | 0.620 | 0.590 | |
| 层次聚类 | bert加权平均句向量 | 0.582 | 0.084 | 0.025 | 0.039 | (这种情况下几乎都预测成了正样本,有10776都为正) |
| 欧式距离FCM | tfidf加权word2vec句向量 | 0.583 | 0.440 | 0.908 | 0.592 | |
| 层次聚类 | tfidf加权word2vec句向量 | 0.536 | 0.413 | 0.921 | 0.570 | |
| 欧式距离FCM | 平均加权word2vec句向量 | 0.776 | 0.637 | 0.766 | 0.695 | |
| 层次聚类 | 平均加权word2vec句向量 | 0.778 | 0.728 | 0.532 | 0.615 | |
| KNN | 平均加权word2vec句向量 | 0.786 | 0.676 | 0.690 | 0.683 | |
| 余弦距离FCM | 平均加权word2vec句向量 | 0.752 | 0.595 | 0.808 | 0.685 | |
用svm的方法达到了0.815的准确率
是否可以让某一个概率大于某个值时,才认为是1
snownlp:
我们首先不用机器学习方法,我们用一个第三库(snownlp),这个库可以直接对文本进行情感分析(记得安装),使用方法也是很简单。返回的是积极性的概率。
|
|
词向量+聚类的模式还能用于领域内的 concept identification (有这样的论文)。
欧式距离( Euclidean distance )和余弦距离( Cosine similarity)评价的两个向量间的不同方面,欧式距离注重的是向量不同维度上的大小,而余弦距离注重的是向量间的方向和夹角。在聚类算法中我们评估不同距离函数的影响。
舆情监控:在聚完类后,可以在每一类别中选择出最具代表性的句子,在每一类中计算出相关度最高(或者前几名)的句子来查看效果。相关度函数如下所示,也可以在聚类完成后可以选择每一类中排名靠前的类别作为最终的预测值,或者是模糊聚类中根据隶属度值大于某一个阈值来确定最终的预测值,也可以最终选择出最终的排名靠前的句子生成摘要作为对某一新闻事件的评价(或者设计某一个指标来表示这一新闻事件的舆情正负值)。(以上是来自Bert-summary的灵感)是否可以用于新冠病毒的舆情分析。能不能爬取微博上的关于新冠病毒的微博内容,做一个舆情分析。
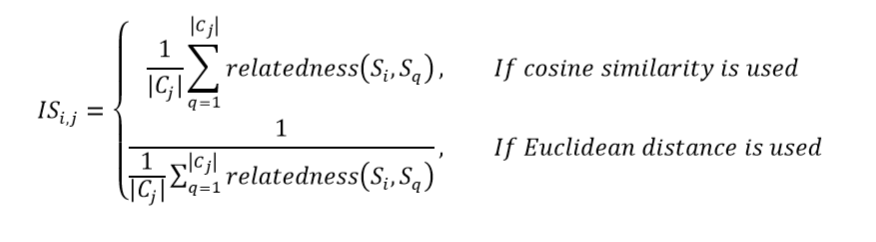
对句子聚类后某一类别的总数可能代表着这些句子对文章的重要性。
问题:(1)在用jieba分词时,是否有必要去掉长度为1的词,另外在word2vec的过程中,长度为1的词是否被忽略掉了?另外去除stopword时,貌似没有去掉,见问题(3)
结果:测试集(前2400条数据为测试集)
(2)在得到平均加权句向量后,利用PCA或者SVD提取句向量后的特征后,会不会有更好的表现?
(3)tfidf平均加权是否合理?情感分析中词频最高的词是不是具有感情色彩,经过分析,在word2vec中频率较高的几个词如下所示:
| 了 | 9394 |
|---|---|
| 的 | 7835 |
| 很 | 2256 |
| 都 | 2193 |
| 是 | 2172 |
| 我 | 2019 |
| 也 | 1901 |
| 还 | 1827 |
| 好 | 1721 |
代码为:
|
|
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/%E6%83%85%E6%84%9F%E5%88%86%E6%9E%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。