cs224n笔记 Lecture10
cs224n笔记 Lecture10 -(Textual) Question Answerin
问答系统(Question Answering)实际需求很多,比如我们常用的谷歌搜索就可看做是问答系统。通常我们可以将问答系统看做两部分:从海量的文件中,找到与问题相关的可能包含回答的文件,这一过程是传统的information retrieval;从文件或段落中找到相关的答案,这一过程也被称作Reading Comprehension阅读理解,也是这一讲关注的重点
1.SQuAD(Stanford Question Answering Dataset )
Reading Comprehension需要数据是Passage即文字段落,Question问题以及相应的Answer回答。SQuAD就是这样的数据集。对于每个问题都有人类提供的三个标准答案,为了评估问答模型,有两个metric:
(1)Exact Match(EM),即模型回答与任意一个标准答案匹配即计数为1,否则为零。统计整体的准确率。
(2)F1,即将模型答案与标准答案当做bag of words,计算 ,
,并计算它们的harmonic mean
,然后对所有问题的F1求平均值。F1评价规则很少基于选择与人类选择的跨度完全相同的跨度,而跨度容易受到各种影响,包括换行,相对来说F1是更可靠的评价指标。两种指标都忽略了标点和介词(a,an,the)。SQuAD存在其局限性:
(1).答案需直接截取自段落中的文字,没有是非判断、计数等问题。
(2).问题的选择依赖于段落,可能与实际中的信息获取需求不同那个。
(3).几乎没有跨句子之间的理解与推断。
2019年SQuAD 1.0版本的数据集中BERT类型的模型指标已经超过了人类的表现,SQuAD 数据集有了2.0版本。
2.Stanford Attentive Reader
1.0版本的数据集中答案基本在段落中,在2.0版本中引入了一些问题在段落中是没有答案的,对于这类问题,当模型输出没有答案时得分1,否则为0。
针对SQuAD数据集开发的QA系统——Stanford Attentive Reader。该系统目前虽然不是最好性能,但它包含QA的基本模块,可以作为QA的一个baseline模型。Stanford Attentive Reader是斯坦福在2016年的ACL会议上的发布的一个机器阅读理解模型,其思路是:首先模型对问题q进行表征的方法如下,输入是q种每个词的词向量,然后使用一个Bi-LSTM提取句子特征,由于是双向的LSTM,所以模型把正向和反向的LSTM的最后一个隐状态拼接起来,作为对整个句子的表征。
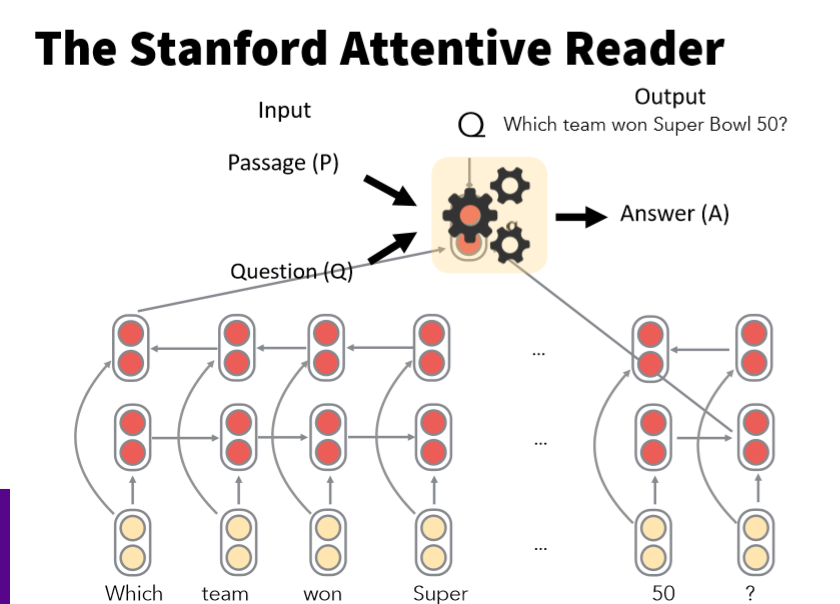
由于SQuAD数据集的回答都是描述段落中的一个span,那么,模型只需要预测出这个span在P中的起始位置和终止位置即可,上一步我们得到的句子的表征向量q,下一步,我们对描述P也使用Bi-LSTM,得到描述P中每个单词的表征向量。然后,对每个单词对应的特征向量与问题的特征向量进行Attention操作,分别得到推测答案起始位置与终止位置的attention score。另外,在计算Attention score的时候,不是简单的向量点积,而是采用了线性变换的方法,增加了参数W,具体方法如下所示:
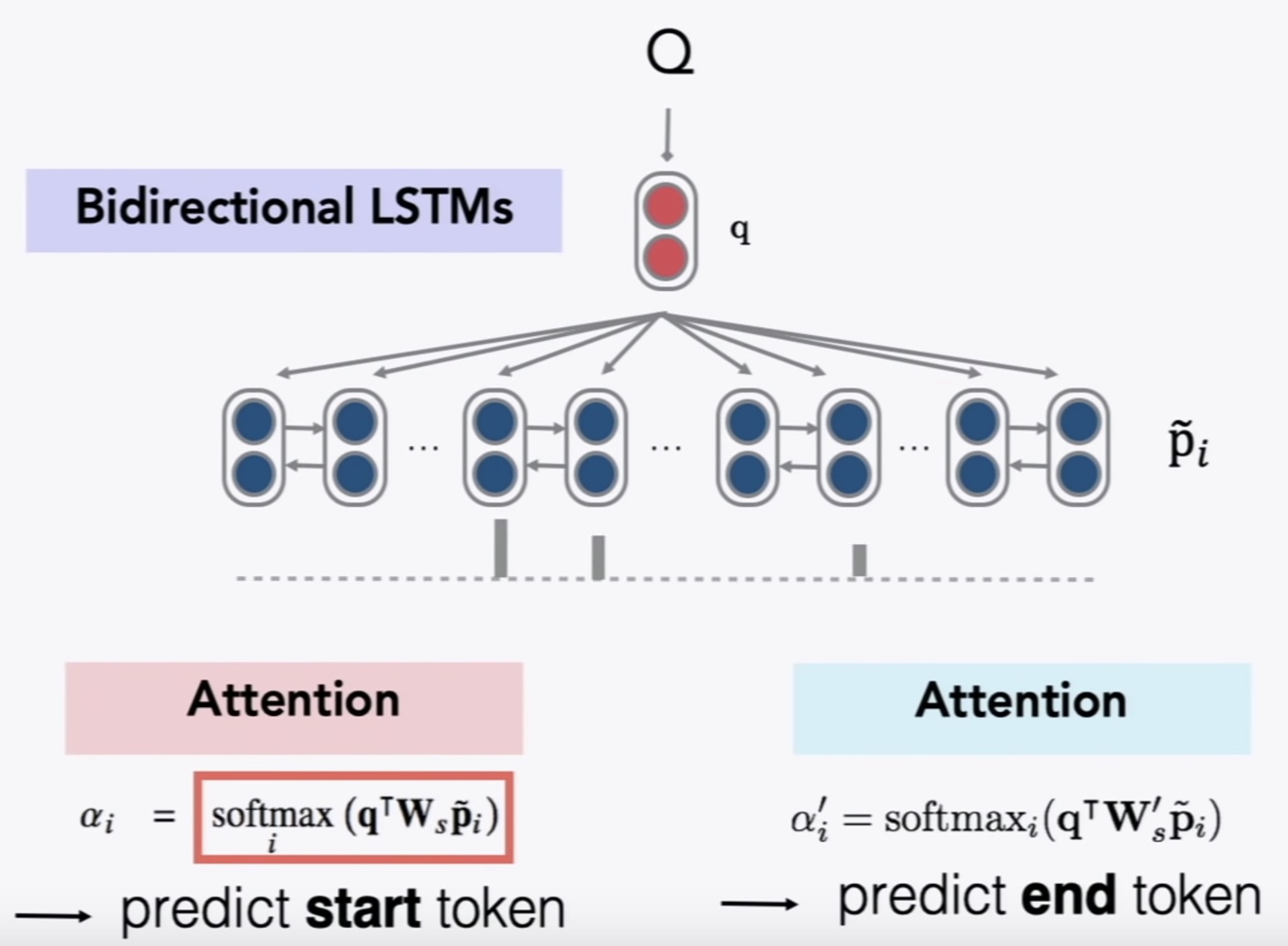
后来,Chris Manning组又推出了升级版本Stanford Attentive Reader++,主要包括两个方面。首先,对表征问题的网络进行了改进,问题的特征向量不仅包含Bi-LSTM的两个尾结点的隐状态,而是包含整个问题所有隐状态的加权平均,而且网络层数增加到了3层。其次,对描述P的表征方面,原来的输入只包含词向量,现在还包含语言特征(如POS、NER的标签)、词频、以及近义词的相似度等,改进版模型性能提升了不少。
3.BiDAF(Bi-Directional Attention Flow)
另一个比较流行的QA系统是BiDAF,其模型结构如下:
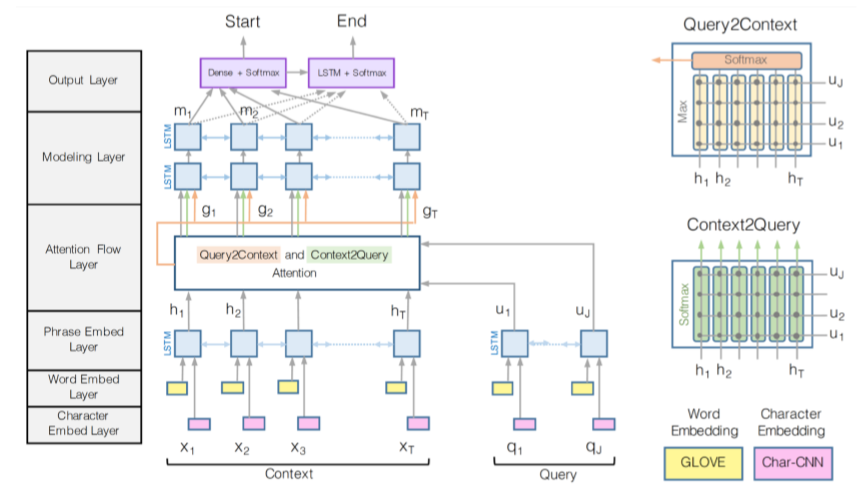
其核心思想是Attention应该是双向的,既有从Context(即passage)到Query(即Question)的attention,又有从Query到Context的attention。首先计算similarity matrix:

由此,我们得到了Attention Flow Layer 的输出:
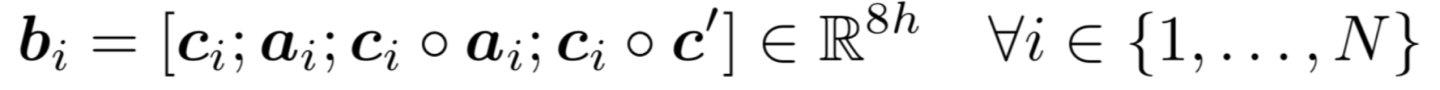
再对其进行多层LSTM与Softmax得到相应的输出。更近期的发展基本上是更复杂的结构以及attention的各种结合。对于embedding的提取方面,也更多采用contextual embedding,收到了很好的效果,关于contextual embedding如Elmo,BERT等会在第13讲详细讲解。
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/cs224n%E7%AC%94%E8%AE%B0-lecture10/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。