Cs224n笔记-lecture6
lecture6 Language Models and Recurrent Nerual Networks
1.language model:就是根据已知序列推测下一个单词(或序列)的问题。输入法、浏览器搜索都有语言模型(根据你输入的单词推测下一个单词或短语)。
2.n-grams:最经典的language model是n-gram,它是基于多个单词在一起使用的统计特性,推测下一个单词时运用了条件概率公式,条件概率公式中为了避免概率为0或者不存在,运用了平滑(即在分母上加上一个比较小的数,加一平滑、线性插值平滑)和backoff的技巧。n-grams有存储和稀疏性问题。
3.神经LM(和编码器很像)。
4.RNN:处理序列信息,共享权重和偏差;核心公式如下:
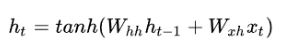
上述公式包括两部分的输入,一部分为当前时间步的输入Xt,另一部分为上一时刻的状态值(相当于记忆值)。每一时间步的两个输入部分的权重向量是相同的,这减小了训练成本。循环神经元的计算步骤如下:
- 将输入时间步提供给网络,也就是提供给网络Xt;
- 接下来利用输入和前一时刻的状态计算当前状态,也就是ht;
- 当前状态变成下一步的前一状态ht-1;
- 我们可以执行上面的步骤任意多次(主要取决于任务需要),然后组合从前面所有步骤中得到的信息;
- 一旦所有时间步都完成了,最后的状态用来计算输出yt;
- 输出与真实标签进行比较并得到误差;
- 误差通过后向传播对权重进行升级更新,进而网络训练完成。
RNN反向传播的过程中总的误差是每一个时间步的误差的和,RNN会有梯度消失的问题,梯度消失的原因是权重共享,在对权重矩阵求偏导时,由于每一个时间步的权重矩阵都是同一个,所以根据求导法则,导数是每个时间步对权重的导数之和。导数一般是和权重相乘的形式,当权重在0-1的时候就容易出现梯度消失,大于1就是梯度爆炸,如何解决,后面的LSTM会改善此情况。
另外RNN是串行结构,不能并行计算,计算较慢。
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/cs224n%E7%AC%94%E8%AE%B0-lecture6/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。