Cs224n笔记 Lecture7
lecture7笔记-vanishing gradients and fancy Rnns
1.梯度消失:由于链式法则(chain rule),在对深层网络反向传播梯度时,可能会出现梯度越乘越小的情况,此即为梯度消失。RNN中的梯度消失和一般的深层神经网络的梯度消失概念有所不同,原因在于RNN权重共享,总梯度为各个时间步的梯度之和,所以总的梯度一般不会消失,而是梯度越穿越弱,来自远距离的梯度消失。RNN因为不断的乘以相同的权重矩阵,梯度消失问题更加严重。
梯度消失的问题:来自远层网络的梯度丢失,因为它比来自附近的梯度小得多,所以权重更新只受附近梯度的影响。梯度爆炸也是如次,梯度爆炸的最好结果是网络无法训练,最坏的结果是权重值为Nah无法更新权重值。
2.解决梯度消失的方法可以有尝试改变激活函数,例如用Relu函数或者LeakyRelu函数代替sigmoid函数,另外在一般的深层网络中可以通过加入层与层之间的连接来缓解梯度消失问题,例如"Resnet”、“Densenet"或者:“HighwayNet”; 解决梯度爆炸一个方案时Gradient clipping:即如果在梯度大于某一阈值,则在SGD更新之前按比例缩小梯度值,梯度下降方向认识原来的方向,伪代码如下:

3.对于梯度消失问题,解决的基本思路是设置一些存储单元来更有效的进行长程信息的存储,基于此提出了RNN的进化结构:LSTM和GRU。
4.LSTM(long short term memory):LSTM加入了一个新的模块cell state 来存储长程的信息,加入了3个gate来控制信息的擦除,写入和读取。LSTM的公式如下:
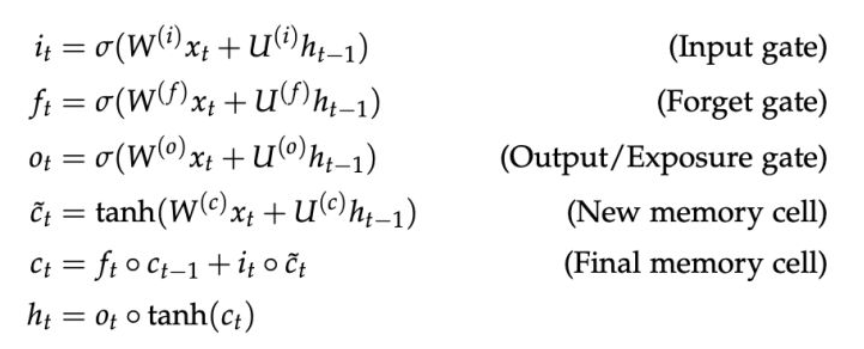
New memeory cell 通过将新输入的x_t与代表之前context的hidden state h_t-1结合生成新的memory;
Input gate i_t决定了新的信息(输入)是否有保留的价值;
Forget gate f-t 决定了之前的cell state 有多少值得保留的信息;
Final memory cell c_t 通过将forget gate与前memory cell作元素积得到了前memory cell需要传递下去的信息,并与input gate和新的memory cell的元素积求和。极端情况是forget gate值为1,则之前的memory cell的全部信息都会传递下去,使得梯度消失问题不复存在; 三门结构的激活函数是sigmoid函数,sigmoid函数的范围是0到1,当sigmoid函数取值接近0时,表示信息不能通过gate,反之,接近1时表示信息可以通过gate。
Output gate o_t 决定了memory cell 中有多少信息需要保存在hidden state中。
单个LSTM的结构如下图所示:
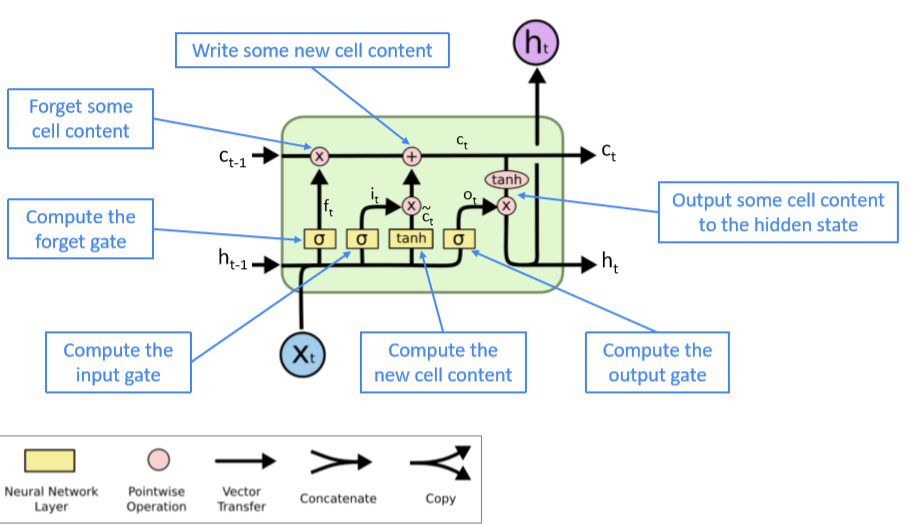
LSTM在2013-2015年在多个NLP任务中取得了State of art 的结果,后来逐渐被"Transfomer"结构所取代。
5.GRU(Gated Recurrent Units)在2014年被提出,作为一个更简单的对LSTM的替代,去掉了cell state。GRU可以看作是将LSTM中的forget gate和input gate合并成了一个update gate,同时将cell state 也合并到hidden state中。公式如下所示:
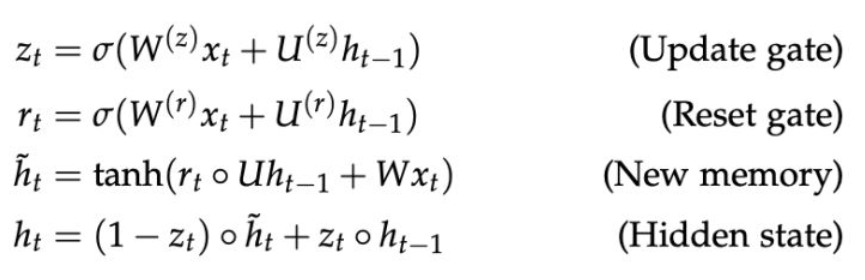
虽然还存在RNN的很多其他变种,但是LSTM与RNN是最广泛应用的。最大的区别就是GRU有更少的参数,更便于计算,对于模型效果方面,两者类似。通常我们可以从LSTM开始,如果需要提升效率的话再准换成GRU。
6.RNN还存在其他的变体,例如双向RNN-BiRNN。一般的RNN只是单向的,RNN只考虑了单侧的信息,为了克服这个缺点,提出了双向RNN,它同时考虑了输入的上下文信息,结构如下图所示:
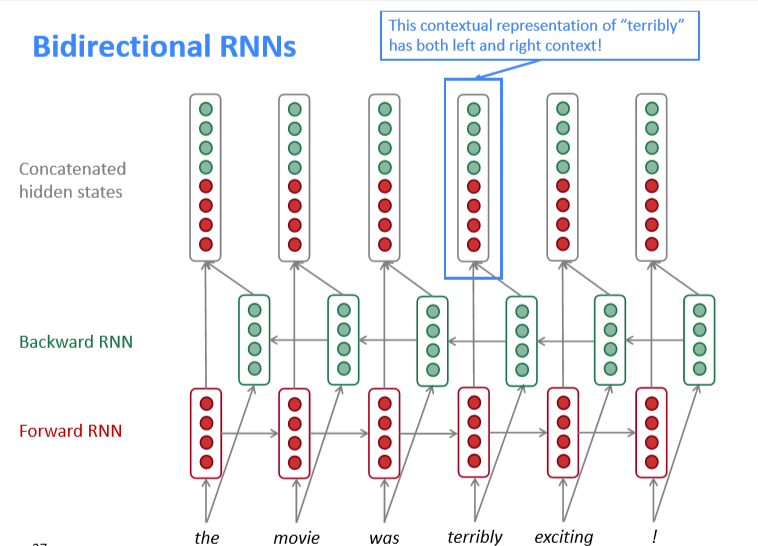
BiRNN只有当有全部的输入序列时才起作用(同时含有上下文信息),在语言模型(language model)中很难运用,因为它只有左侧的信息。双向编码的模型中最成功的是BERT,后续会学习。
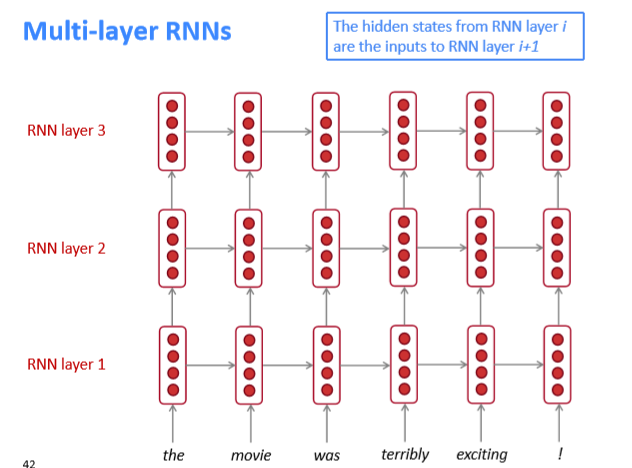
RNN的变体还有多层RNN——Multi-RNN(Stacked-RNN),它从另一个维度"加深"了RNN,提高了其表达能力,结构如下图:
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/cs224n%E7%AC%94%E8%AE%B0-lecture7/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。