Cs224n笔记 Lecture8
lecture8笔记-Machine Translation,Sequence-to-sequence and attention
1.machine tranlation:从一个语言翻译到另一个语言,起源于冷战时期,最初是将俄语翻译成英语。最初是基于规则的,按照词典的对照转换;后来逐渐发展出按统计规则的SMT,但SMT太复杂了,最终神经机器翻译NMT横空出世,机器翻译迎来了新的发展。
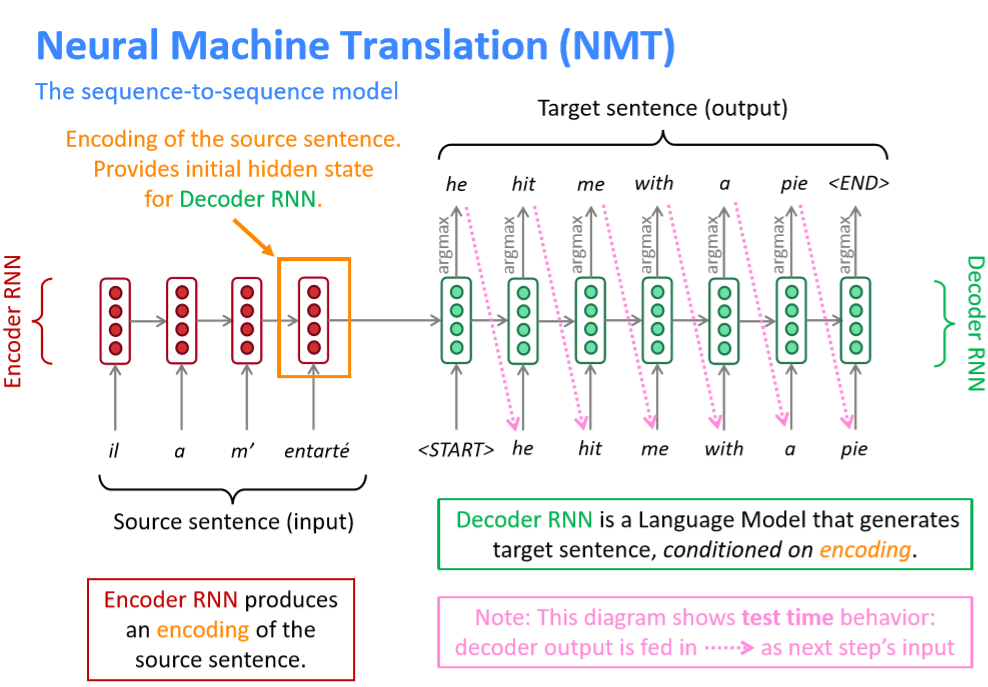
2.NMT依赖于sequence-to-sequence的结构,即通过一个RNN作为encoder将输入的源语言转化为某表征空间中的向量,再通过另一个RNN作为decoder将其转化为目标语言中的句子。我们可以将decoder看做预测目标句子y的下一个单词的语言模型,同时其概率依赖于源句子的encoding,一个将法语翻译成英语的Seq2Seq模型如下图所示:
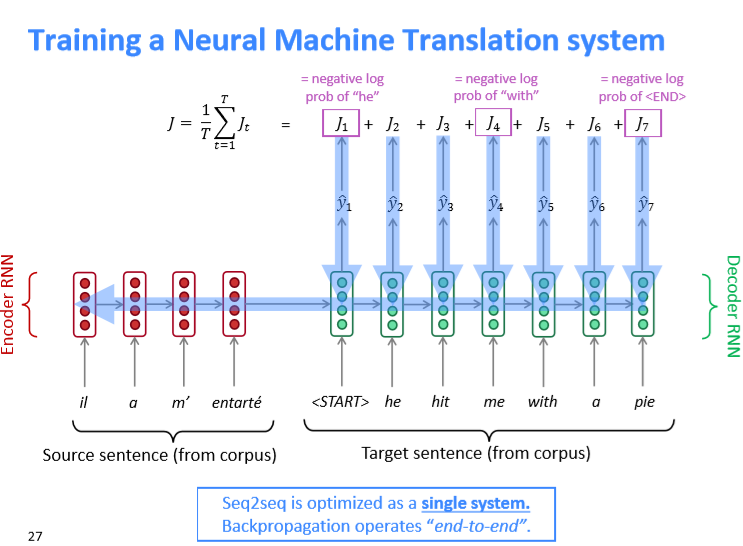
训练上述模型时,损失函数与语言模型类似,即各步目标单词的log probability的相反数的平均值,在反向传播过程中,梯度可以传播到encoder层,即所谓的"end-to-end”,训练过程如下图所示:
在decoder时,如果每一步都选取概率最大的单词并将其作为下一步decoder的输入(greedy decoder),这时对于翻译整个句子来说可能不是最优的选择,只要有一个时间步的单词出错后,后面的单词可能都会受影响。如何解决这个问题?
解决上述问题的办法是Beam search decoding,核心思想是在解码的每一步,保留k个最有可能的选项(k为beam size),k一般取值为5-10。最有可能的选项是通过分数值选择出来的,每个可能单词的分数值是负数,所以分数越低越好。这里存在翻译的句子长度越长分数值越高的情况,为了避免倾向于选择长翻译,在评分时需要是做一个归一化:
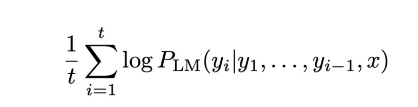
当k=2时,beam search decoding的流程如下所示,注意每一步都是选择前k个最有可能的选项。
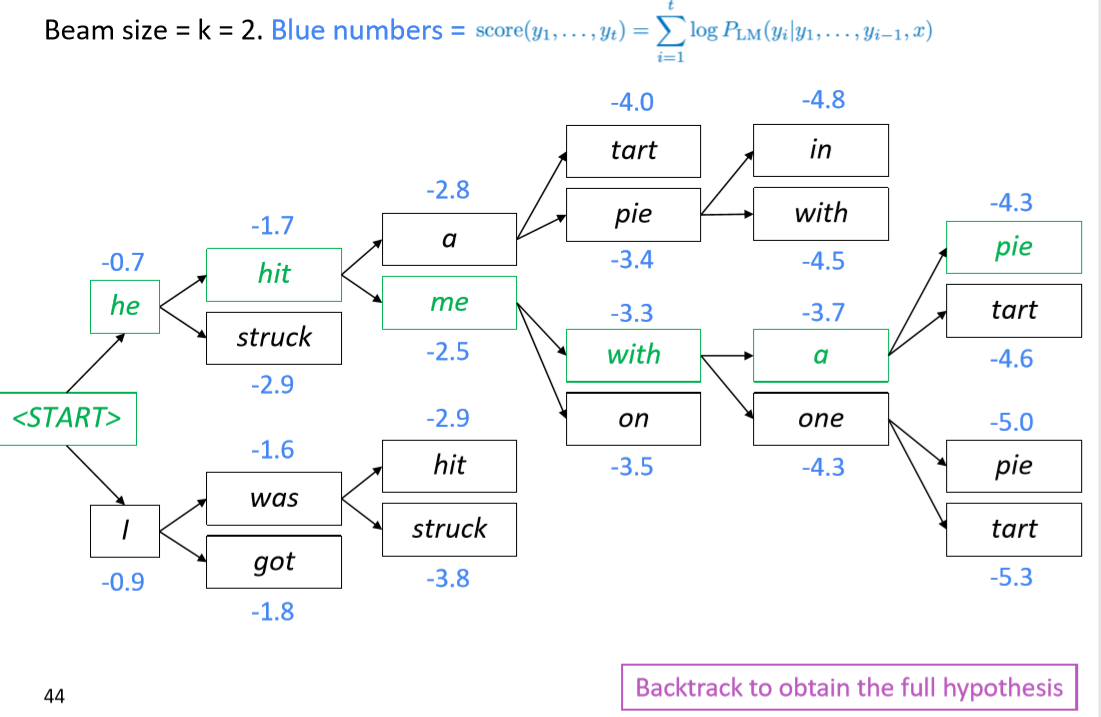
绿色字体即为最后选择出的得分最高的翻译句子;beam search结束的标志与greedy seach结束的标志不一样,greedy search结束的标志是出现 token,在beam search会出现多个,此时结束的停止条件为达到预设的时间步T或者得到了至少n个预先设定的翻译句子。
NMT的缺点是不可解释性以及不能用规则来引导翻译过程。
3.衡量机器翻译好坏的指标是BLEU(Bilingual Evaluation Understudy),基本思想是看machine translation的n-gram在人工翻译中出现的概率。

BLEU这个指标并不是完美的,有很多关于评价机器翻译的指标也在研究中。
4.在NMT的发展过程中,attention机制的出现解决了seq2seq模型的信息"瓶颈”,在seq2seq模型中,我们用Encoder RNN的最后一个神经元的隐状态作为Decoder RNN的初始隐状态,也就是说Encoder的最后一个隐状态向量需要承载源句子的所有信息,成为整个模型的“信息”瓶颈。
宏观上来说,Attention把Decoder RNN的每个隐层和Encoder RNN的每个隐层直接连起来了,还是“减少中间商赚差价”的思路,由于有这个捷径,Encoder RNN的最后一个隐状态不再是“信息”瓶颈,信息还可以通过Attention的很多“直连”线路进行传输。

Attention的过程如下所示:

Attention机制不仅只用于机器翻译中,在其他NLP领域也有应用,attention更一般的定义如下:
给定一系列values向量集合H,再给定一个查询(query)s,query决定着values中哪一个向量需要被注意。一般使用s和H中的每一个向量做点积,得到s对H的注意力分布,然后用这个分布对H进行平均加权的到H的attention output
另外,attention机制的公式还有许多其他的变体,但总体思路是不变的。
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/cs224n%E7%AC%94%E8%AE%B0-lecture8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。