Django及Keras中的LSTM
Django及keras中的LSTM
1.keras中的LSTM
最近在做光伏功率预测的项目时需要用到keras中的LSTM函数,本文对LSTM中的参数做个记录。
keras.layers.LSTM 类中有两个常用但不容易理解的参数,分别是 return_sequences 和 return_state。对于两个参数,官方定义如下:
return_sequences: 布尔值。是返回输出序列中的最后一个输出,还是全部序列。return_state: 布尔值。除了输出之外是否返回最后一个状态。
keras.layers.LSTM 默认 return_sequences=False 和 return_state=False。此时只会返回最终ht值。LSTM中的参数units代表转化后输出outputs的维数,不是cell的个数,可以理解为训练参数W的维数,经过转化将输入转化为固定的维数。Keras中RepeatVector相当于将输出重复多次,将一个2D的向量转化为3D的向量。下面举一个栗子:
|
|
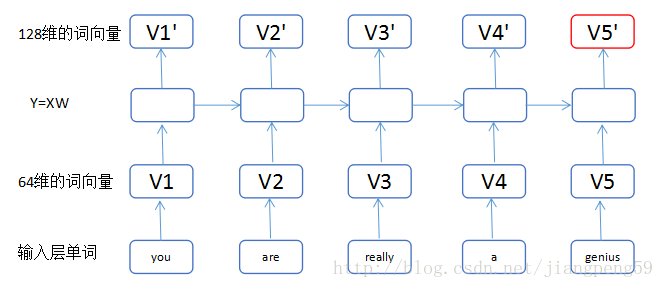
(1)我们把输入的单词,转换为维度64的词向量,小矩形的数目即单词的个数input_length ; (2)通过第一个LSTM中的Y=XW,这里输入为维度64,输出为维度128,而return_sequences=True,我们可以获得5个128维的词向量V1’..V5’ ; (3)通过第二个LSTM,此时输入为V1’..V5’都为128维,经转换后得到V1”..V5”为256维,最后因为return_sequences=False,所以只输出了最后一个红色的词向量 V5”。
2.django
在做项目时,最好与github同步,与github同步的办法是:可以先在github上建立一个存储库,例如在github上创建一个demo库,然后在终端执行下述命令:
git clone https://github.com/zdhwg/demo.git
然后本地文件中就有了demo文件夹,在此文件夹中进行编码。在此文件夹下创建一个test文件夹,用于存放项目文件,然后进入到该文件,并在该目录中启动Django项目,命名为server。
mkdir test
cd test
django-admin startproject server
另外可以用django-admin查看所有的django命令。用以下命令来初始化服务器,在web浏览器中输入127.0.0.1:8000时,可以看到django默认的欢迎站点。
cd server
python manage.py runserver
经过一些列上面的操作,已经修改了原文件夹下的文件,下面提交一下新的文件:
git add test/ ###也可以用git add .将全部的更改都记录下来
git commint -m "setup django project"
git push
3.简单机器学习算法
第一步是加载库,重点是joblib保存模型的使用,另外pickle也可以完成类似的功能,在Python中,如果希望透明地存储对象,而不丢失其身份和类型等信息,则需要某种形式的对象序列化,这是一个将任意复杂的对象转成对象的文本和二进制表示的过程。
|
|
数据采用Adult Income数据集。在这个数据集中,ML将被用来根据人口普查数据预测收入是否超过每年5万美元。
|
|
X矩阵有32561行14列,这是我们算法的输入数据,每一行描述一个人。y向量有32561个值,表示年收入是否超过5万每年。在开始数据预处理之前,我们将把数据分成训练和测试子集。我们将使用30%的数据进行测试。
|
|
在应用机器学习算法前,首先进行数据预处理。对于此数据集,主要分为数据的缺失值处理和类别数据的处理。数据缺失值的处理这里采用用最频繁的值填充(还用许多其他的填充方式)。
|
|
train_mode中保存了每一列最频繁的值。然后将数据中的类别进行编号:
|
|
encoders中保存了每一个列下的编号类型,当有新数据进来时,加载encoders即可保证在训练集和测试集中的编码类型一样。数据预处理后,下面进行机器学习算法,
|
|
在训练一个Extra Trees:
|
|
下面要保存我们创建的算法。需要注意的重要一点是,ML算法不仅是rf和et变量(带有模型权值),我们还需要保存预处理变量train_mode和encoders。为了保存,将使用joblib包。
|
|
新建一个ml文件,将所有的代码文件放在里面,然后同步到github。
git add research/*
git commit -am "add ML code and algorithms"
git push
到目前为止已经初始化了默认的django项目和训练好了两个ML算法,下面将ML算法部署到django框架上,并编 使用Django REST框架为ML算法编写REST API。
为了创建Django模型,我们需要创建一个新的app(endpoints):
# run this in test/server directory
python manage.py startapp endpoints
mkdir apps
mv endpoints/ apps/###mv命令为linux系统使用,在windows相当于剪切粘贴。
使用上述命令,我们创建了endpoints应用程序并将其移动到apps目录。我已经添加了apps目录来保持项目的整洁。
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/keras%E4%B8%AD%E7%9A%84LSTM%E5%8F%8ADjango/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。