Keras中embedding层的作用
一、深度学习中embedding层的作用是什么?在做NLP相关工作时经常会与embedding层打交道,在
查阅了有关资料后,将其作用和用法记录如下。
首先,使用embedding主要有两大原因:
1.使用One-hot 方法编码的向量会很高维也很稀疏。假设我们在做自然语言处理(NLP)中遇到了一个
包含2000个词的字典,当使用One-hot编码时,每一个词会被一个包含2000个整数的向量来表示,其中
1999个数字是0,要是我的字典再大一点的话这种方法的计算效率岂不是大打折扣?
2.训练神经网络的过程中,每个嵌入的向量都会得到更新。通过embedding层可以展现多维空间中词
与词之间有多少相似性,这使我们能可视化的了解词语之间的关系,不仅仅是词语,任何能通过嵌入层
Embedding 转换成向量的内容都可以这样做。
下面举例如下:
"deep learning is very deep"
对上述句子使用embedding层,第一步是通过索引对该句子进行编码,对句子中每个不同的单词分配
不同的索引,上述句子会变成下面这样:
1 2 3 4 1
接下来会创建嵌入矩阵,我们要决定每一个索引需要分配多少个“latent factor”(潜在因子),即每个单词
用多长的向量表示,通常情况是长度分配为32和50。此处举例可分配6个潜在因子,那么嵌入矩阵就会变
成这样:

embedding的作用就是将单词”deep"用向量[.32,.02,.48,.21,.56,.15]表示,在训练神经网络的过程中,嵌
入向量也会被不断更新。这样通过embedding我们就可以在高维空间中探索哪些单词之间具有相似性,单
词向量在高维空间的分布如下图所示(通过t-SNE降维技术可将这些相似性可视化):

二、keras中embedding层
实际的embedding操作举例如下:
输入句子样本为“I very happy”,词典即每个单词的索引是[0:pad_word,1:I,2:very,3:happy,4:so,5:sad],嵌
入矩阵

则input X=[1,2,3],然后对X进行one-hot编码:
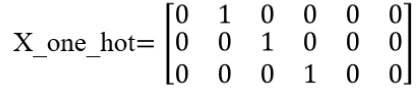
那么对输入X的词向量表示应该是X_one_hot×W,如下所示:

也就是说对于像一个句子样本X=[1,2,3] (1,2,3表示单词在词典中的索引)这样的输入可以先对它one-hot然
后乘上词嵌入矩阵就可得到这个句子的词嵌入向量表示。要想得到好的词向量,我们需要训练的就是这个
矩阵W(shape=(input_dim,output_dim))。Embedding层的作用就是训练这个矩阵W并进行词的嵌入为每
一个词分配与它对应的词向量。这个词嵌入矩阵W可以先随机初始化,然后根据下游任务训练获得,也可
以使用预训练的词嵌入矩阵来初始化它(keras中用weights来为layer初始化任意权重),然后再训练,也可
以直接用预训练的词嵌入矩阵来初始化它并冻结它,不让它变化,不让它可训练(keras中用
trainable=False)。
keras中的embedding层函数:
keras.layers.Embedding(input_dim, output_dim, embeddings_initializer=‘uniform’, embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
主要参数说明:
- input_dim:int,整个词典的大小,或者说唯一单词的个数,当然如果还有一个用于padding的单词那就应加1。
- output_dim:int,嵌入维度,设计的词向量的维度。
- embeddings_initializer:嵌入矩阵的初始化器。
- mask_zero:如果设置为True那么padding的0将不参与计算,默认是False。这个参数可用于解决非等长序列padding噪声到原始数据的问题。
- input_length:序列长度,每个样本都有相同的长度。
注:typora中矩阵的输入格式为:
$$
a = \left[
\matrix{
alpha_1 & test1\\
alpha_2 & test2\\
alpha_3 & test3
}
\right]
$$
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/keras%E4%B8%ADembedding%E5%B1%82%E7%9A%84%E4%BD%9C%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。