微博爬虫
构建微博爬虫系统
本文的主要目的为记录微博爬虫的学习过程,最终的目的为实现爬取微博上的信息,可以完成定向信息的检索,将一定时间内的微博爬取下来。
1.微博数据不同于qq空间和朋友圈,是唯一一个可以爬的社交媒体平台。微博数据中可以爬取到数据维度有:
| 字段 | 说明 |
|---|---|
| weibo_url | 这条微博的URL,可以作为这则微博的唯一标识 |
| user_id | 这则微博作者的ID |
| content | 微博的内容 |
| tool | 发布的工具,一般是手机型号,或者上图中的weibo.com |
| created_at | 微博发表时间 |
| image_group | 微博附带图的URL |
| repost_num | 转发数 |
| comment_num | 评论数 |
| like_num | 点赞数 |
| is_repost | 是否是转发的微博 |
| repost_weibo_url | 如果是转发的微博,源微博的URL |
主要爬取的是上述内容,另外还可以爬取用户数据、评论数据、社交关系等。目前微博一共有三个站点,分别是https://weibo.cn、https://m.weibo.com、https://weibo.com。这三个站点的复杂度逐渐升高,在最简单的weibo.cn上可以实现抓取一个人的微博、社交关系等内容,但是无法实现一个对于本课题至关重要的内容:高级搜索,即在限定时间范围内搜索某一个关键词。(有问题?后文又说可以实现此功能)
2.高级搜索的网址入口
在weibo.cn这个网站上高级搜索的入口为:https://weibo.cn/search/mblog?advanced=mblog&f=s,可以看到这里可以筛选的条件是,类型,用户,时间,注意,这里的时间是以天为单位。可以看到一页有10条搜索的结果,最多显示100页,也就是1000条结果,所以,一次搜索的结果,最多返回1000条微博,这里要注意,搜索之前需要登陆微博。
m.weibo.com这个站点没有设置高级搜索的功能,weibo.com的高级搜索入口为https://s.weibo.com,这里实现以小时为单位的搜索。综上,对于实现高级搜索功能,只能选择weibo.com和weibo.cn,weibo.com的筛选条件更加丰富,包括了地区,时间段更细,以小时为单位。 目测本课题的只需要用到weibo.cn这个站点。
3.微博登陆
前文说到要实现微博的高级搜索功能,必须要首先登陆微博,而微博检测你是否登陆了微博,靠的是检测次Request请求携带的cookie,所以要做的事情,就是登陆微博,获取cookie存下来,然后以后的请求带上这个cookie即可。当然,如果你不会微博自动化登陆,也可以手工登陆,然后复制cookie下来。BUT,这对于批量的账户,你总不能逐个这样做吧….那么如何实现微博的自动化登陆?
微博的登陆操作,具体通过自动化工具 selenium 来实现,它支持Chrome,Firefox和PhantomJS等多种浏览器。好处就是,不用再去分析登陆时候恶心的js加密,解密的过程,直接而且简单,坏处就是效率比较慢,但是我们只是用它来完成登陆并获取cookie的操作,所以效率并不是很重要的事情。
通过selenium编写浏览器的脚本,自动打开微博的手机站(weibo.cn),点击登录,在输入框中填充账号,密码,再点击登录。最后返回cookie即可。
|
|
获取cookie以后,可以保存到数据库中。以后每次request请求,随机从数据库中选一个cookie加上,就免登录了。但是对于在网上买的小号,可能会有验证码的问题,后续可以参考这个回答:https://juejin.im/post/5acf0ffcf265da23826e5e20。需要购买小号,如果遇到特别恶心的验证码就没有办法了。
4.爬虫框架
采用scapy构建爬虫框架,参考:https://github.com/nghuyong/WeiboSpider。微博不封IP,只封账号,所以要想构建千万级别的爬虫系统,只要做一件事情购买大量账号,构建账号池。构建账号池的步骤也非常简单:
-
购买大量账号
-
登陆进微博,保存下cookie 就这两步,以后每次请求,只要随机从账号池中选择一个账号即可。
对于本课题来说仅需单账号的十万级的爬虫系统即可。
|
|
UserAgent是识别浏览器的一串字符串,相当于浏览器的身份证,在利用爬虫爬取网站数据时,频繁更换UserAgent可以避免触发相应的反爬机制。fake-useragent对频繁更换UserAgent提供了很好的支持,可谓防反扒利器。
https://s.weibo.com/weibo?q=肺炎&sort=hot&suball=1×cope=custom:2020-01-013:2020-01-01&Refer=g&page=1
如上所示为https://s.weibo.cn的高级搜索时的url,可以看出其中有几个关键点,包括主题、typeall=1代表搜索模式(是按热度搜索还是按照全部搜索)、时间和页数。该站点的高级搜索功能如下所示:
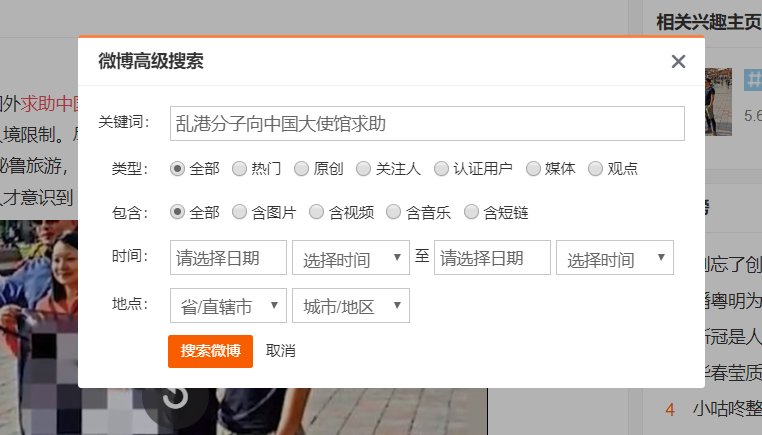
2019年12月31日,武汉市卫健卫发布通告称在华南海鲜市场发现多例肺炎病,这一通报引发了较为广 泛的社会关注,舆论的关注点主要集中于“华南海 鲜市场”、“肺炎”、“传染”等词。需要说明的是,关于此次肺炎的通报在名称上存在一个变动过程,2019年月12月30日~2020年1月10日称不明原因肺 炎、不明原因病毒性肺炎,2020年年1月11日~2月7日称新型冠状病毒感染的肺炎, 2月8日,国务院联防联控机制新闻发布会通报了国家卫健委关于 新冠病毒感染的肺炎暂命名为“新型冠状病毒肺炎”,简称“新冠肺炎”的信息,因此,以“肺炎”为关 键词进行搜索,可以更全面地抓取到各时段关于本次疫情的议题。
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/python%E7%88%AC%E8%99%AB-%E5%BE%AE%E5%8D%9A%E7%88%AC%E8%99%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。