Python爬虫 爬取图片
python爬虫-爬取图片
上次爬取文本的网站是静态网站,今天尝试爬取动态网站上的图片。静态网站和动态网站的区别是什么呢?首先静态网站的特点如下:
- 静态网站是最初的建站方式,浏览者所看到的每个页面是建站者上传到服务器上的一个 html ( htm )文件,这种网站每增加、删除、修改一个页面,都必须重新对服务器的文件进行一次下载上传。网页内容一经发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都是保存在网站服务器上的,也就是说,静态网页是实实在在保存在服务器上的文件,每个网页都是一个独立的文件;
- 静态网页的内容相对稳定,因此容易被搜索引擎检索;
- 静态网页没有数据库的支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作方式比较困难;
- 静态网页的交互性较差,在功能方面有较大的限制。
动态网站的特点如下:
1.交互性:网页会根据用户的要求和选择而动态地改变和响应,浏览器作为客户端,成为一个动态交流的桥梁,动态网页的交互性也是今后 Web 发展的潮流。
2.自动更新:即无须手动更新 HTML 文档,便会自动生成新页面,可以大大节省工作量。
3.因时因人而变:即当不同时间、不同用户访问同一网址时会出现不同页面。
简单来说,静态网站是固定的html页面,谁访问都是一样的结果。动态网站是有动态生成的内容在页面中的,可以实现一定的定制化。比方说访问网站的页面有个表,不同时间的访问是不同的表现。具体的内容实现,是在访问服务器的时候,不是请求的html页面或下载东西等等,而是需要调用servlet。动态网站使用动态加载常用的手段就是通过调用JavaScript来实现的。本博客就是静态网站,它基于hugo实现,下面我们爬取一个动态图片网站上的图片。
一.
(1)目标url:https://unsplash.com/,这是一个免费高清壁纸分享的动态网站,通过审查元素可以知道图片都放在标签中,这个标签有有、alt、src、class、style属性,其中src属性存放的就是我们需要的图片保存地址,我们根据这个地址就可以进行图片的下载。那么正常的下载过程如下:
- 使用requeusts获取整个网页的HTML信息;
- 使用Beautiful Soup解析HTML信息,找到所有``标签,提取src属性,获取图片存放地址;
- 根据图片存放地址,下载图片。
但是我们爬取得到的html信息和在网站审查元素时的结果完全不一样,这是因为这个网站的所有图片都是动态加载的!动态加载有一部分的目的就是为了反爬虫。
(2)由于目标网站是动态加载的,所以我们可以通过抓包找到负责动态加载图片的JavaScript脚本。抓包工具有很多,小到最常用的web调试工具firebug,达到通用的强大的抓包工具wireshark。这里我们使用更为高效的Fiddler,什么是Fiddler?
Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。在做毕设的时候,爬取数据时遇到了翻页url不变的网站,该网站为动态网站,最后通过抓包分析,像网站发送页码进行翻页,解决了此问题。
Fiddler遇到了点问题,这里使用谷歌浏览器的network工具来进行抓包,如下所示:
右半部分是网站服务器返回的信息,这些信息和用爬虫返回的html信息完全一样,这个不是我们所需要的链接。
Fiddler问题解决了,Fiddler在抓包https网站时,需要在option选项中先勾选允许抓取https流量。通过Fiddler抓包,我们得到一个JavaScript请求,如下所示,服务器返回的是一个Json格式的内容,json格式是一种轻量级的数据交换格式,起到封装数据的作用,易于人阅读和编写,同时也易于机器解析和生成。
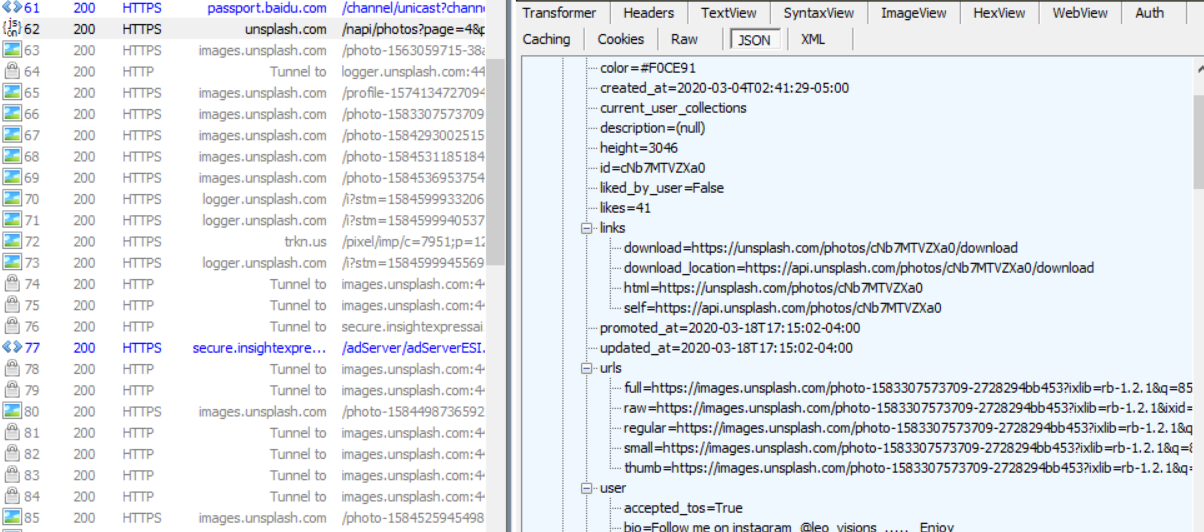
从上图可以看到,服务器返回的内容有图片的id,大小,链接等信息,但图片的链接有很多,因此需要确定以下哪一个是对应的图片的链接。如下所示,我们点击图片的下载,然后抓包分析,

发送的请求为:
https://unsplash.com/photos/eeTJKC_wz34/download?force=trues
通过Fiddler抓包,我们发现,点击不同图片的下载按钮,GET请求的地址都是不同的。但是它们很有规律,就是中间有一段代码是不一样的,其他地方都一样,中间的代码即为json数据中的照片的id,我们只要解析出每个照片的id,就可以获得图片下载的请求地址,然后根据这个请求地址,我们就可以下载图片了。怎么编程提取这些json数据呢?我们也是分步完成:
- 获取整个json数据
- 解析json数据
|
|
通过上述代码可以直接输出json内容,没有出现报错的问题。如果出现SSL认证错误,一个非常简单的解决这个认证错误的方法就是设置requests.get()方法的verify参数。这个参数默认设置为True,也就是执行认证。我们将其设置为False,可以绕过认证。如果GET请求失败,还有可能是需要验证验证Request Headers,这也是反爬虫的手段之一,下面是Headers中的部分参数,测试需要哪一个参数,我们在requests.get()中添加相应的headers参数即可。
-
User-Agent:这里面存放浏览器的信息。可以看到上图的参数值,它表示我是通过Windows的Chrome浏览器,访问的这个服务器。如果我们不设置这个参数,用Python程序直接发送GET请求,服务器接受到的User-Agent信息就会是一个包含python字样的User-Agent。如果后台设计者验证这个User-Agent参数是否合法,不让带Python字样的User-Agent访问,这样就起到了反爬虫的作用。这是一个最简单的,最常用的反爬虫手段。
-
Referer:这个参数也可以用于反爬虫,它表示这个请求是从哪发出的。可以看到我们通过浏览器访问网站,这个请求是从
https://unsplash.com/,这个地址发出的。如果后台设计者,验证这个参数,对于不是从这个地址跳转过来的请求一律禁止访问,这样就也起到了反爬虫的作用。 -
authorization:这个参数是基于AAA模型中的身份验证信息允许访问一种资源的行为。在我们用浏览器访问的时候,服务器会为访问者分配这个用户ID。如果后台设计者,验证这个参数,对于没有用户ID的请求一律禁止访问,这样就又起到了反爬虫的作用。
获得json数据后,用html = json.loads(req.text)就可以解析出来了,这样得到的html是一个list,里面有我们所需要的"id”,将其中的id提取出来用于构造下载url即可。最后代码整理如下:
|
|
下载速度比较慢,其他爬取动态网站的方法也是如此。
代码中with可以用来关闭文件,数据库资源。只要实现了__enter__() 和 __exit__()这两个方法的类都可以轻松创建上下文管理器,就能使用with。with语句体执行之前运行__enter__方法,在with语句体执行完后运行__exit__方法。如果一个类连这两个方法都没有,是没资格使用with的。 那么contextlib.closing()会帮一个没有上述方法的类加上__enter__()和__exit__(),使其满足with的条件
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/python%E7%88%AC%E8%99%AB-%E7%88%AC%E5%8F%96%E5%9B%BE%E7%89%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。