Python爬虫-爬取文本
python 爬虫-爬取文本
以前做项目时需要爬虫,总是现学现用,现在抽个时间把爬虫的知识点整理一下,以便以后查看。
网络爬虫(web spider)根据网页地址(URL)爬取网页内容,在用爬虫之前,一般需要到指定的URL处审查元素(鼠标右键),查看目标网页的HTML格式分布,HTML是浏览器搭建网页的代码,后面会再介绍HTML的构成。
python中有很多集成的库用于爬虫,一般我们可以通过requests+BeautifulSoup的组合来完成一整套的爬取工 作,requests的工作是爬取HTML中的内容,beautifulsoup的工作是查找HTML中的内容并将其转化成需要的格式。requests库的基础方法如下图所示:
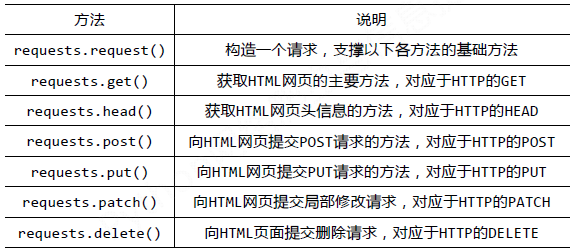
requests库中最常用的两个HTTP请求是get和post,get和post都是两种发送请求的办法,区别如下:
(1)它们之间最明显的区别是GET把参数包含在URL中,POST通过request body传递参数。
(2)GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
(3)GET请求在URL中传送的参数是有长度限制的,而POST没有。
(4)对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据),即GET产生一个TCP数据包,POST产生两个TCP数据包。
BeautifulSoup库最主要的功能是从网页抓取数据,BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。通过以下代码调用:
|
|
BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:(1)Tag (2) NavigableString (3) BeautifulSoup (4) Comment
Tag是HTML中一个个标签,我们可以利用 soup 加标签名轻松地获取这些标签的内容,这些对象的类型是bs4.element.Tag。但是注意,它查找的是在所有内容中的第一个符合要求的标签。对于 Tag,它有两个重要的属性,是 name 和 attrs,同样后面加上name或者attrs可以得到对象的属性。
NavigableString 的意思是在得到标签的内容后如果要获取标签中的内容,可通过.string的方式得到。
BeautifulSoup对象表示的是一个文档的内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性。(后文中会使用)
Comment 对象是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号。(没有理解)
-
爬取文本内容
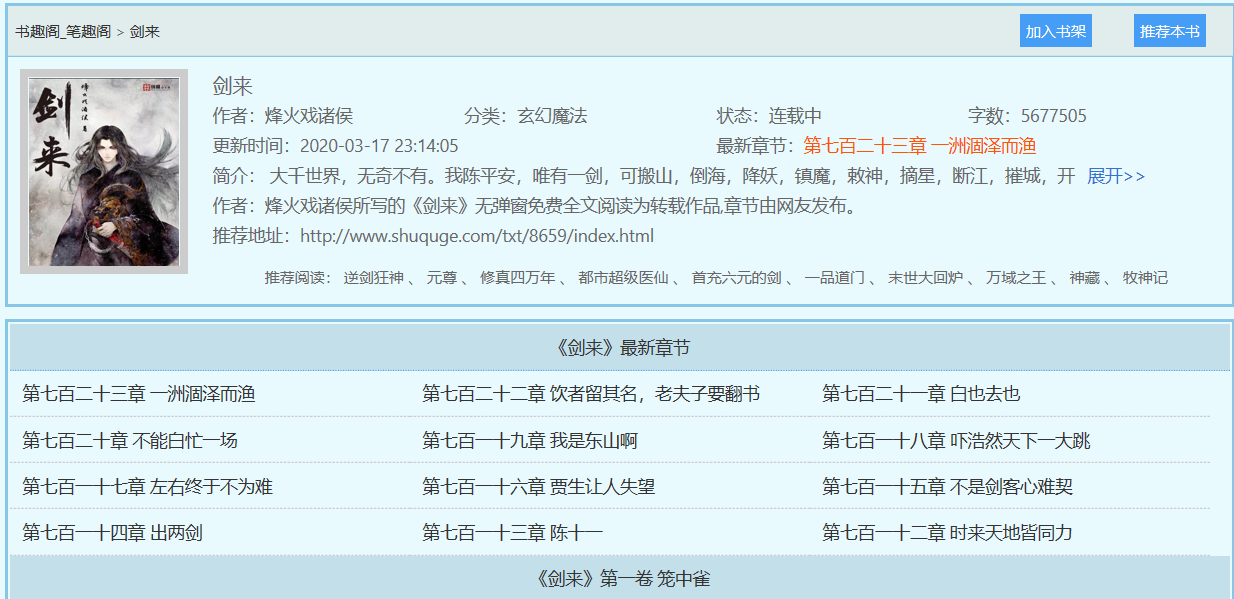
目标网址:http://www.shuquge.com/,这是一个免费的小说网站-笔趣阁,我们的目标是爬取《剑来》小说,它可以在线看,但不能下载。
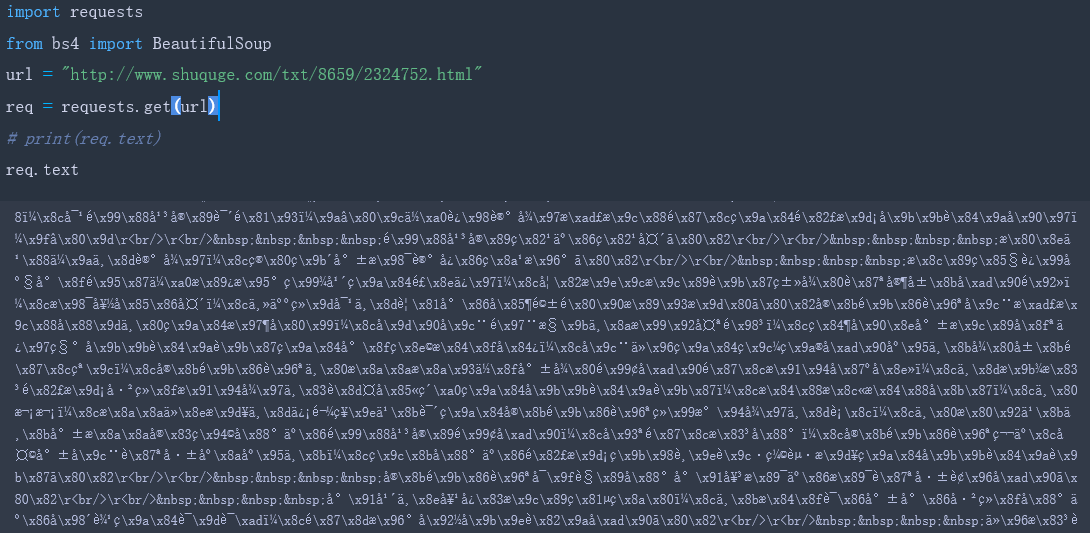
(1)下面尝试爬取第一章内容的HTML信息,如下所示,爬取得到的内容是一堆乱码,下面通过BeautifulSoup将乱码转化成文本并将多余的符号去掉,得到我们想要的内容。
(2)要得到正文内容,首先在目标网页上审查元素,查看我们的目标网页,会得到以下的内容:

可以看出文章的所有内容都放到了html标签-div下面,class和id是标签div的属性,而"showtext"和"content"是属性值,区分不同的div标签就是通过标签不同的属性值。因此可以通过标签名和其独有的属性值来匹配到多需内容,在(1)中我们看到返回的中文内容乱码了,可能是因为数据源的编码声明不规范,可以手动设置返回数据的正确编码:req.encoding='utf-8’,如下所示:
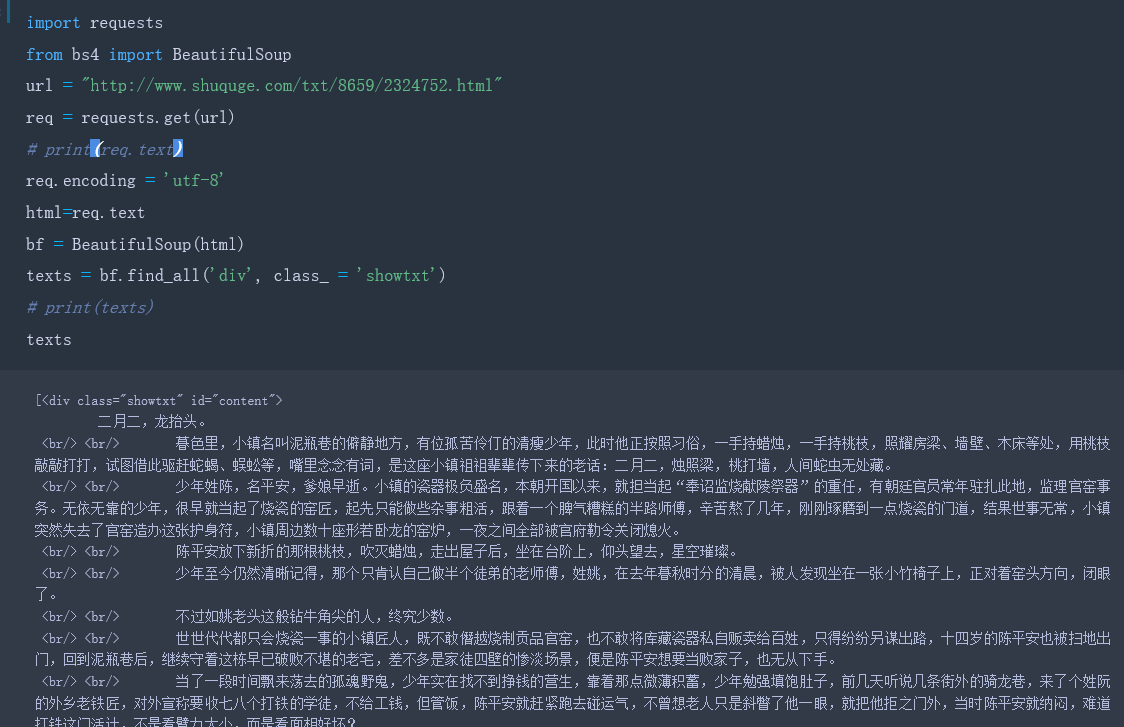
BeautifulSoup函数里的参数就是我们已经获得的html信息,然后我们使用find_all方法,获得html信息中所有class属性为showtxt的div标签。find_all方法的第一个参数是获取的标签名,第二个参数class_是标签的属性,因为python中class是关键字,为了防止冲突,这里使用class_表示标签的class属性。我们已经匹配到了正文内容,但是里面还有各种div标签名,br标签,以及各种空格等不需要的东西,下面去除不必要的符号:
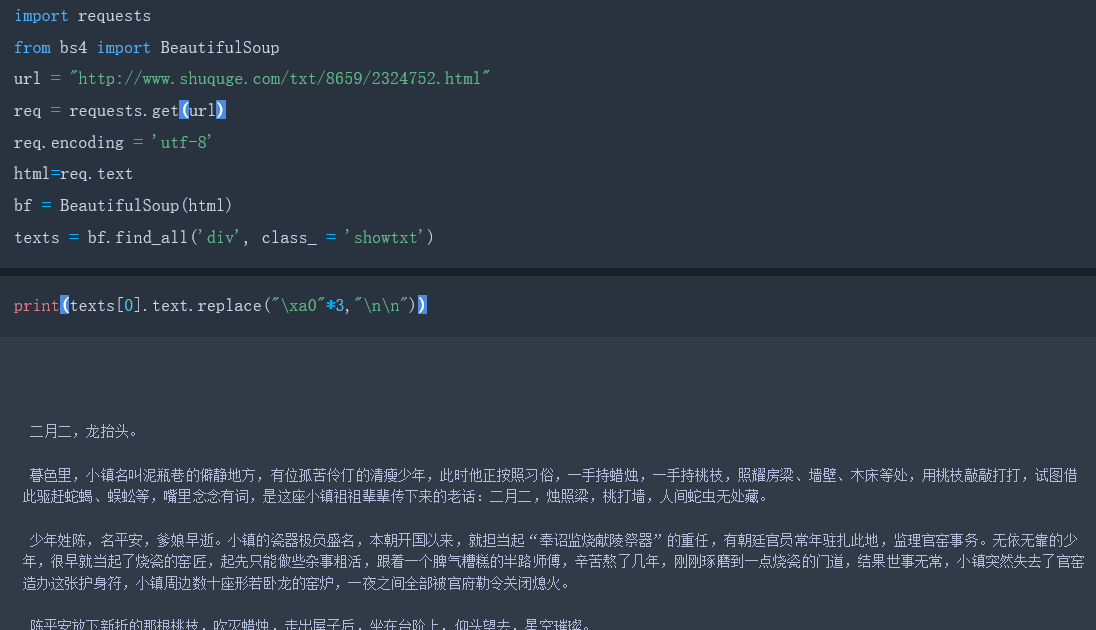
find_all匹配的返回的结果是一个列表。提取匹配结果后,使用text属性,提取文本内容,滤除br标签。随后使用replace方法,剔除空格,替换为回车进行分段。
在得到第一章的正文内容后,我们下一步爬取整本书。
(3)我们首先分析目录,审查每一章题目的元素,如下所示:

通过审查元素,我们发现章节名字放在了dd标签下,而dd标签又在class属性为listmain的div标签下。HTML中有子节点父节点的概念,这类div为dd的父节点,dd为a节点的父节点,标签符号总是成对出现的(+)。标签定义了一个超链接,herf属性表示超链接的目标。herf属性值是每一张章节的URL的后半部分,这样根据属性值可以得到每一章节的链接和名称了。
总结一下:小说每章的链接放在了class属性为listmain的标签中。链接具体位置放在html->body->div->dl->dd->a的href属性中。先匹配class属性为listmain的标签,再匹配标签。编写代码如下:
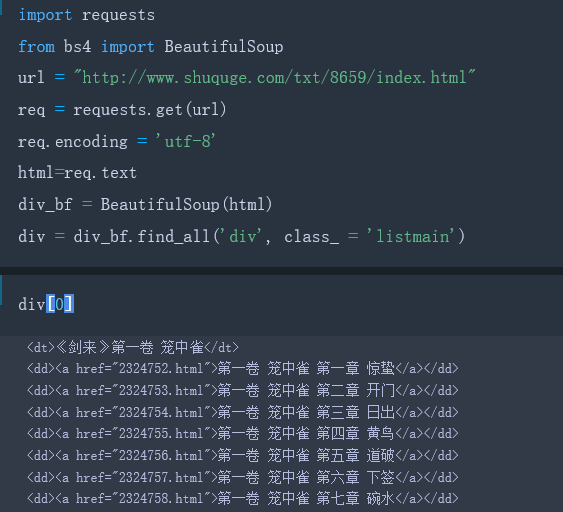
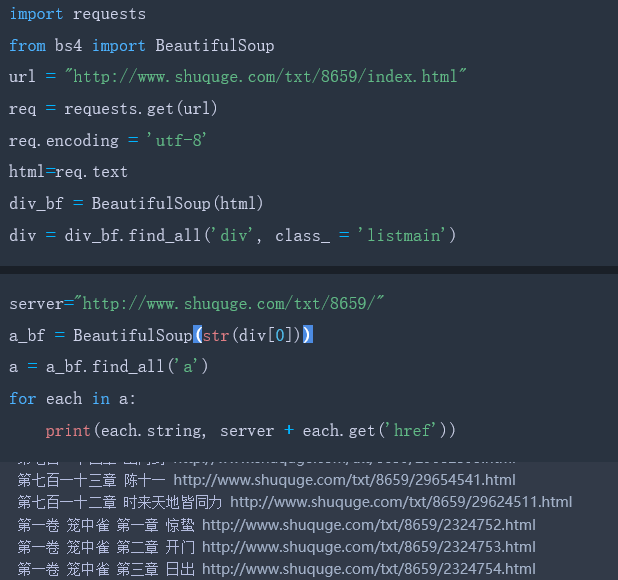
接下来一步是提取数herf中的链接地址和章节名:
<a href="2324753.html">第一卷 笼中雀 第二章 开门</a>
方法很简单,对Beautiful Soup返回的匹配结果a,使用a.get(‘href’)方法就能获取href的属性值,使用a.string就能获取章节名,因为find_all返回的是一个列表,里边存放了很多的标签,所以使用for循环遍历每个标签并打印出来,运行结果如下。编写代码如下:
(4)现在每个章节的内容都可以得到,最后将上面所有的内容整合在一起,爬取整本书的代码如下:
|
|
用电脑问题打开txt可能会有乱码问题,这可能因为写字板默认是用ansi编码打文档,如果文档是非ansi编码的,那自然打开会出现乱码,解决办法是打开后再转存以下就可以了。
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/python%E7%88%AC%E8%99%AB-%E7%88%AC%E5%8F%96%E6%96%87%E6%9C%AC/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。