Python爬虫 爬取视频
现在很多视频网站采用流媒体技术进行播放视频,一种常见的方案是m3u8文件+ts文件 。 m3u8是苹果公司推出一种视频播放标准,是m3u的一种,不过编码方式是utf-8,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求。
本来是打算按照教程爬取一个解析VIP视频的网站上的视频,但是原网站已经找不到了。经过一番努力,找到了另一个vip解析网站:http://www.qmaile.com/。
我们以爱奇艺视频的加勒比海盗5为例:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1。这个视频必须要有VIP才能看完整版,但我们可以通过上述VIP视频解析网站来在线看这些VIP视频,但是这个网站只提供了在线解析视频的功能,没有提供下载接口,如果想把视频下载下来,我们就可以利用网络爬虫进行抓包,将视频下载下来。
一、
经过测试发现不同的视频有不同的加载方式,例如神奇动物:格林德沃之罪(https://www.iqiyi.com/v_19rr7p5sag.html?vfrm=pcw_playpage&vfrmblk=F&vfrmrst=80521_correlation_star_image2),通过抓包解析VIP的这个动作,我们可以直接得到这个视频在服务器上的缓存地址如下所示,根据这个地址,我们就可以轻松下载视频了。
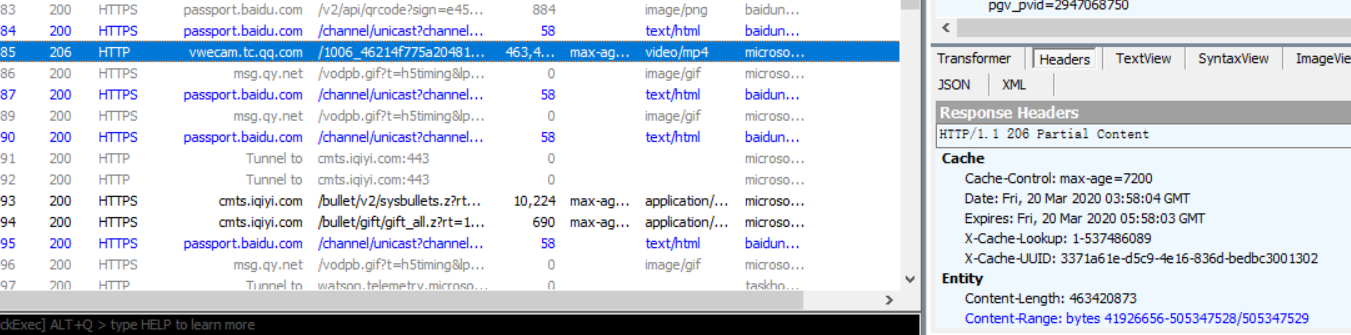
进入这个url后,可以直接转存视频,如下所示:

也可以利用爬虫下载这个视频,下载速度很快,代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import requests,re, json, sys
from urllib import request
def _progress(block_num, block_size, total_size):
'''回调函数
@block_num: 已经下载的数据块
@block_size: 数据块的大小
@total_size: 远程文件的大小
'''
sys.stdout.write('\r>> Downloading %s %.1f%%' % (filename,
float(block_num * block_size) / float(total_size) * 100.0))
def video_download(url, filename):
request.urlretrieve(url=url,filename=filename,reporthook=_progress)
if __name__ == '__main__':
url="http://vwecam.tc.qq.com/1006_46214f775a20481da80278d41621dbbb.f0.mp4?vkey=12A318FDC135A83A15C7FD5051B126034A0381F693160CC0A5467B4F101D15844FA7F0437AD984902A90E95552A9876BB8BDB5B43ED9F703&rf=mobile.qzone.qq.com"
filename = '神奇动物'
print('%s下载中:' % filename)
video_download(url, filename+'.mp4')
print('\n下载完成!')
|
要注意爬取的时效性比较低,其url每次解析都在变化,所以当长时间为爬取需要在抓包分析其变化后的url。另外如果遇到<403>Forbidden的情况,需要加入headers,headers的内容也可以通过抓包提取。
二、
接下来爬取通过另一种方式加载的视频,即m3u8文件+ts文件 ,以加勒比海盗5为例:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1。在抓包时发现它是以流媒体的形式加载的,当视频解析成功开始播放时,抓包如下:

我们获取一下改url的内容:

可以看到有一系列的4WudJ1vi1366000.ts等,将其替换掉m3u8链接后面的index.m3u8就是ts文件的链接了,同时 ts文件会按照顺序编号 。爬取ts文件的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import requests
# from contextlib import closing
def getPlayList(url):
html=requests.get(url).text
ts=html.split()
ts_1ist=ts[5:][::2]
return ts_1ist
# def dl_ts(ts_url, i):
# with closing(requests.get(ts_url, stream=True, verify = False)) as r:
# with open('%d.ts' % i, 'ab+') as f:
# for chunk in r.iter_content(chunk_size = 1024):#当流下载时,这是优先推荐的获取内容方式。
# if chunk:
# f.write(chunk)
# f.flush()#清空缓冲区
def dl_ts(ts_url, i):
r = requests.get(ts_url)
with open(str(i+1)+".ts", 'wb') as f:
f.write(r.content)
f.close()
if __name__ == '__main__':
url="https://sohu.com-v-sohu.com/20170915/PehRQmVm/1000kb/hls/index.m3u8"
ts_list=getPlayList(url)
length=len(ts_list)
# for i in range(length):
for i in range(100):
ts_url = "https://sohu.com-v-sohu.com/20170915/PehRQmVm/1000kb/hls/{}" .format(ts_list[i])
print("下载第{}个".format(i+1))
dl_ts(ts_url, i)
|
下载比较慢,在下载完成后,将所有的ts文件合并到一起即可,合并代码如下所示:
1
2
3
4
5
6
7
8
9
10
|
import os
def tsToMp4():
print("开始合并...")
root = "D://python code//数据爬取//"
outdir = "output"
os.chdir(root)
# copy /b F:\f\*.ts E:\f\new.ts
os.system("copy /b *.ts new.mp4")
# os.system("move new.mp4 {}".format(outdir))
print("结束合并...")
|
大功告成!(ps:下载速度太慢了)
后又尝试多进程爬取,代码如下,后面再继续改进:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
from time import sleep
import socket
import requests
from contextlib import closing
from multiprocessing import Process
class CatchVideo(object):
def __init__(self):
self.url="https://sohu.com-v-sohu.com/20170915/PehRQmVm/1000kb/hls/index.m3u8"
self.ts_list=[]
def getPlayList(self):
html=requests.get(self.url).text
ts=html.split()
self.ts_1ist=ts[5:][::2]
def set_url(self,i):
tsurl = "https://sohu.com-v-sohu.com/20170915/PehRQmVm/1000kb/hls/{}" .format(self.ts_list[i])
return tsurl
def dl_ts(self,url_1, i):
with closing(requests.get(url_1, stream=True, verify = False)) as r:
with open('%d.ts' % i, 'ab+') as f:
for chunk in r.iter_content(chunk_size = 1024):#当流下载时,这是优先推荐的获取内容方式。
if chunk:
f.write(chunk)
f.flush()#清空缓冲区
def start_work(self,i):
url_1=set_url(i)
try:
dl_ts(url_1,i)
print(str(i) + ".ts success")
sleep(1)
except socket.timeout as e:
print(e.reason)
dl_ts(url_1,i)
if __name__ == '__main__':
catch_video = CatchVideo()
socket.setdefaulttimeout(20)# 设置socket层超时时间20秒
I = 0
while I < 7747+1:
#7747为总的长度
# 5个进程并发运行
p_l = [Process(target=catch_video.start_work, args=(i,)) for i in range(I, I+3)]
for p in p_l:
p.start()
for p in p_l:
p.join()
I = I + 5
|