理解Glove模型
Glove是词的向量化表示方法之一,常用的词的向量化表示方法有:word2vec、glove、ELMo、BERT。首先先介绍一下除Glove以外的其他三种方法。
word2vec
word2vec是2013年提出的方法, 它的核心思想是通过词的上下文得到词的向量化表示,有两种方法:CBOW(通过附近词预测中心词)、Skip-gram(通过中心词预测附近的词),如下图所示:
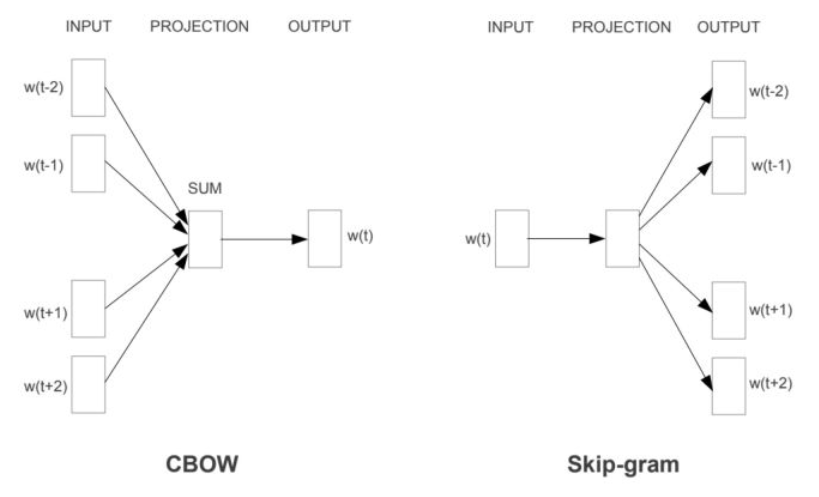
在用CBOW或者Skip-gram方法训练词向量的过程中,因为词汇表大和样本不均衡,一般会采用多层softmax或负采样优化的方法。
ELMo
下面介绍ELMo方法, word2vec和glove存在一个问题,**即词在不同的语境下其实有不同的含义,**而这两个模型词在不同语境下的向量表示是相同的,Elmo就是针对这一点进行了优化。ELMo的作者认为ELMo有两个优势:
- 能够学习到单词用法的复杂特性。
- 学习到这些复杂用法在不同上下文的变化。
针对点1,作者是通过多层的stack LSTM去学习词的复杂用法,不同层的output可以获得不同层次的词法特征。针对点2,作者通过pre-train+fine tuning的方式实现,先在大语料库上进行pre-train,再在下游任务的语料库上进行fine tuning。
ELMo的具体实现方式:
ELMo来自于Embedding from Language Models的简写,此处的Language Models具体的实现方式是LSTM,一开始的训练目标可以表示为如下的形式:
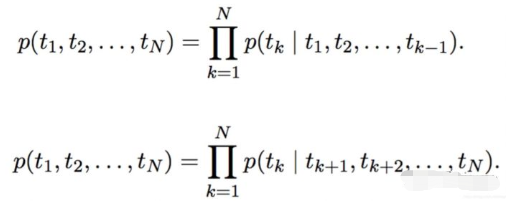
具体来说是通过双方向预测单词,前向过程中,用1~k-1的词去预测第k个词,后向过程中,用k+1~N的词去预测第k个词。具体的编码方式作者采用了LSTM,可以表示为:
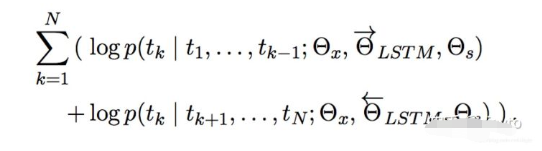
通过LSTM编码Tokens,用第k-1个Token的隐藏层输出预测第k个Token,预测的方法是用一个softmax做一个分类,其中 是token的向量表示,
是softmax的参数。这种双向LSTM堆叠L层,stack-RNN的方式也就是每一层隐藏层的输出作为下一层的输入。 那么对于每个Token会有2L+1个向量表示,双向所以每层2个,+1是token输出层的向量表示,作者将2L+1个向量组合起来得到ELMo每个token的向量表示:
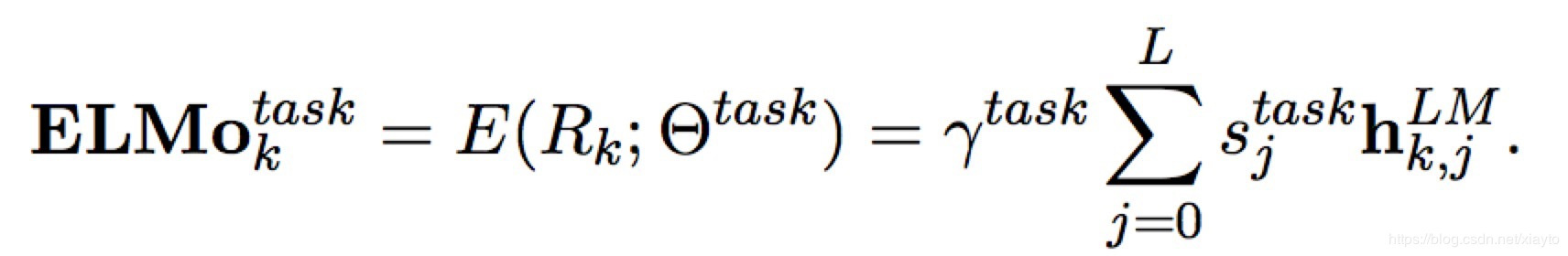
其中 是对于token k的第j层的隐藏层输出,当j=0的时候表示输入层token的向量表示,这个向量表示可以通过CNN或Highway等网络引入char-level的特征。
是一个softmax的归一化,
是一个放缩的参数,可以让目标模型对ELMo的向量进行放缩。 经过两层双向LSTM提取特征,又针对下游任务定制词向量,效果比word2vec和glove要好也在情理之中
BERT
在NLP中,一共有4大类任务:
- 序列标注:分词/词性标注/命名实体识别…
- 分类任务:文本分类/情感分析…
- 句子关系判断:自然语言推理/深度文本匹配/问答系统…
- 生成式任务:机器翻译/文本摘要生成…
BERT为这4大类任务的前3个都设计了简单至极的下游接口,省去了各种花哨的Attention、stack等复杂的网络结构,且实验效果全面取得了大幅度的提升。 BERT的工作方式与ELMo的工作方式是类似的,都是现在大规模的语料库中pre-train,然后将下游任务输入,进行比较轻量级的fine-tuning。 BERT的工作方式采用了Transformer(Attention is all you need),详细的工作方式后续再在介绍。下面着重介绍Glove模型:
Glove
Cbow/Skip-Gram 是一个local context window的方法,缺乏了整体的词和词的关系,负样本采用sample的方式会缺失词的关系信息。另外,直接训练Skip-Gram类型的算法,很容易使得高曝光词汇得到过多的权重。Global Vector(Glove)融合了矩阵分解Latent Semantic Analysis (LSA)的全局统计信息和local context window优势。融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重。skip-gram、CBOW每次都是用一个窗口中的信息更新出词向量,但是Glove则是用了全局的信息(共线矩阵),也就是多个窗口进行更新。下面详细介绍。
方法概述:首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。设共现矩阵为X,其元素为Xi,j。Xi,j的意义是在整个语料库中,单词i和单词j共同出现在一个窗口中的次数。
举个栗子:设有语料库
i love you but you love him i am sad
这个小小的语料库只有1个句子,涉及到7个单词:i、love、you、but、him、am、sad。如果我们采用一个窗口宽度为5(左右长度都为2)的统计窗口,那么就有以下窗口内容:
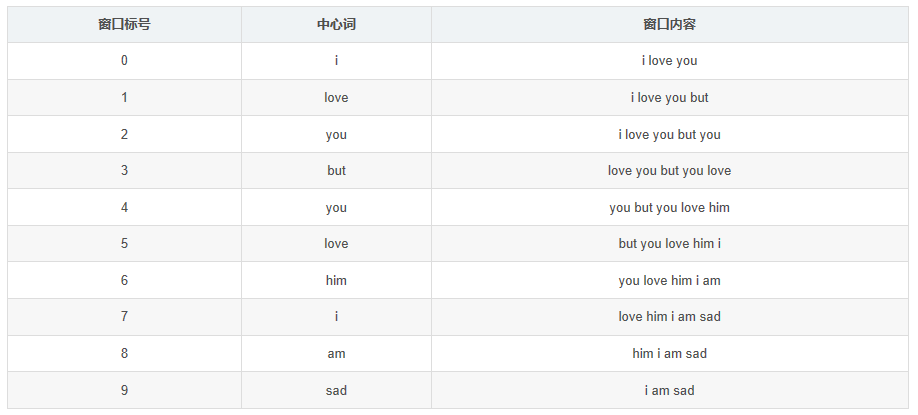
窗口0、1长度小于5是因为中心词左侧内容少于2个,同理窗口8、9长度也小于5。 以窗口5为例说明如何构造共现矩阵:中心词为love,语境词为but、you、him、i;则执行:
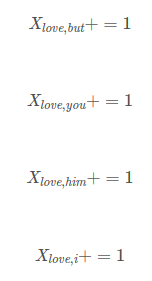
使用窗口将整个语料库遍历一遍,即可得到共现矩阵X。
使用Glove模型训练词向量
先看模型,代价函数长这个样子:
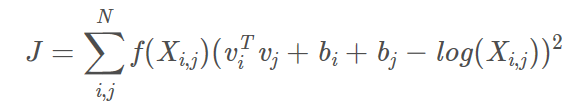
vi,vj是单词i和单词j的词向量,bi,bj是两个标量(作者定义的偏差项),f是权重函数(具体函数公式及功能后面介绍),N是词汇表的大小(共现矩阵维度为N*N)。可以看到,GloVe模型没有使用神经网络的方法。
模型怎么来的
那么作者为什么这么构造模型呢?首先定义几个符号:
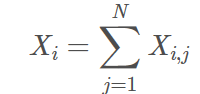
其实就是矩阵单词i那一行的和;
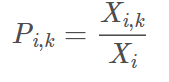
条件概率,表示单词k出现在单词i语境中的概率;
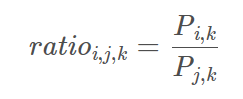
两个条件概率的比率。
作者发现,两个条件概率的比率这个指标是有规律的,规律统计在下表:

思想:假设我们已经得到了词向量,如果用词向量vi、vj、vk通过某种函数计算ratio_i,j,k,能够得到和上表中一样的规律的话,就意味着我们的词向量中蕴含了共现矩阵中所蕴含的信息。设用词向量vi、vj 、vk计算ratio_i,j,k的函数为g(vi,vj,vk) (我们先不去管具体的函数形式),那么应该有:

但是上面的代价函数太过于复杂,计算复杂度很高(为N的3次方),下面考虑化简它:作者的思路是这样的:
1.要考虑单词i和单词j之间的关系,函数g中要有vi-vj这样的一项;(在线性空间中考虑两个向量的相似性,这样的差项是一个合理的选择)
2.ratio_i,j,k是一个变量,但输入是向量,所以可通过内积项将向量变为标量,所以有(vi-vj)^T*vk这么一项。
3.最后在函数的外面一层加上一个指数运算exp(),套上exp()的目的如下:

然后最终的化简方法就是分别让分子相等,分母相等:

化简后的复杂度大大减小(为N的平方),加入指数函数运算的目的是让差形式转化为商形式,最终可以分别让分子和分母相等。
化简之后还有一个问题:

以上即为整个glove的模型。
(写公式也太复杂了)
- 原文作者:WG
- 原文链接:https://zdhwg.github.io/post/%E7%90%86%E8%A7%A3Glove%E6%A8%A1%E5%9E%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。